एक यादृच्छिक चर का प्रसरण. असतत यादृच्छिक चर का फैलाव। मानक विचलन
जहां σ 2 j, jth समूह का इंट्राग्रुप विचरण है।
असमूहीकृत डेटा के लिए अवशिष्ट विचरण- सन्निकटन सटीकता का माप, यानी मूल डेटा के प्रतिगमन रेखा का सन्निकटन: 
जहां y(t) - प्रवृत्ति समीकरण के अनुसार पूर्वानुमान; y t - प्रारंभिक गतिशीलता श्रृंखला; n – अंकों की संख्या; पी - प्रतिगमन समीकरण गुणांक की संख्या (व्याख्यात्मक चर की संख्या)।
इस उदाहरण में इसे कहा जाता है निष्पक्ष विचरण अनुमानक.
उदाहरण क्रमांक 1. टैरिफ श्रेणियों के अनुसार एक एसोसिएशन के तीन उद्यमों के श्रमिकों का वितरण निम्नलिखित डेटा द्वारा विशेषता है:
| श्रमिक की टैरिफ श्रेणी | उद्यम में श्रमिकों की संख्या | ||
| उद्यम 1 | उद्यम 2 | उद्यम 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
परिभाषित करना:
1. प्रत्येक उद्यम के लिए भिन्नता (अंतर-समूह भिन्नता);
2. समूह के भीतर भिन्नताओं का औसत;
3. अंतरसमूह फैलाव;
4. कुल विचरण.
समाधान।
समस्या का समाधान शुरू करने से पहले, यह पता लगाना आवश्यक है कि कौन सी सुविधा प्रभावी है और कौन सी तथ्यात्मक है। विचाराधीन उदाहरण में, परिणामी विशेषता "टैरिफ श्रेणी" है, और कारक विशेषता "उद्यम की संख्या (नाम)" है।
फिर हमारे पास तीन समूह (उद्यम) हैं, जिनके लिए समूह औसत और इंट्राग्रुप भिन्नताओं की गणना करना आवश्यक है:

| कंपनी | समूह औसत, | समूह के भीतर भिन्नता, |
| 1 | 4 | 1,8 |
समूह के भीतर भिन्नताओं का औसत ( अवशिष्ट विचरण) की गणना सूत्र का उपयोग करके की जाएगी:

आप कहां गणना कर सकते हैं:

या:
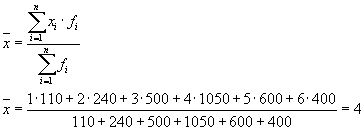
तब:
कुल विचरण इसके बराबर होगा: s 2 = 1.6 + 0 = 1.6।
कुल विचरण की गणना निम्नलिखित दो सूत्रों में से किसी एक का उपयोग करके भी की जा सकती है:

व्यावहारिक समस्याओं को हल करते समय, किसी को अक्सर एक ऐसी सुविधा से निपटना पड़ता है जो केवल दो वैकल्पिक मान लेती है। इस मामले में, हम किसी विशेषता के किसी विशेष मूल्य के भार के बारे में बात नहीं कर रहे हैं, बल्कि समग्रता में उसके हिस्से के बारे में बात कर रहे हैं। यदि अध्ययन की जा रही विशेषता रखने वाली जनसंख्या इकाइयों का अनुपात "द्वारा दर्शाया गया है" आर", और जिनके पास नहीं है - के माध्यम से" क्यू", तो विचरण की गणना सूत्र का उपयोग करके की जा सकती है:
एस 2 = पी×क्यू
उदाहरण क्रमांक 2. एक टीम में छह श्रमिकों के उत्पादन डेटा के आधार पर, अंतरसमूह भिन्नता निर्धारित करें और यदि कुल भिन्नता 12.2 है तो उनकी श्रम उत्पादकता पर कार्य शिफ्ट के प्रभाव का मूल्यांकन करें।
| टीम कार्यकर्ता नं. | कार्यकर्ता आउटपुट, पीसी। | |
| प्रथम पाली में | दूसरी पाली में | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
समाधान. आरंभिक डेटा
| एक्स | च 1 | च 2 | च 3 | च 4 | च 5 | च 6 | कुल |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| कुल | 31 | 33 | 37 | 37 | 40 | 38 |
फिर हमारे पास 6 समूह हैं जिनके लिए समूह माध्य और इंट्राग्रुप प्रसरणों की गणना करना आवश्यक है।
1. प्रत्येक समूह का औसत मान ज्ञात कीजिए.
2. प्रत्येक समूह का माध्य वर्ग ज्ञात कीजिए.
आइए गणना परिणामों को एक तालिका में संक्षेपित करें:
| समूह संख्या | समूह औसत | समूह के भीतर भिन्नता |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. समूह के भीतर भिन्नतासमूह के अंतर्निहित कारक को छोड़कर, सभी कारकों के प्रभाव में एक समूह के भीतर अध्ययन की गई (परिणामात्मक) विशेषता के परिवर्तन (भिन्नता) की विशेषता है:
इंट्राग्रुप भिन्नताओं के औसत की गणना सूत्र का उपयोग करके की जाएगी:
4. अंतरसमूह विचरणसमूह का आधार बनाने वाले कारक (तथ्यात्मक विशेषता) के प्रभाव के तहत अध्ययन की गई (परिणामात्मक) विशेषता के परिवर्तन (भिन्नता) की विशेषता है।
हम अंतरसमूह विचरण को इस प्रकार परिभाषित करते हैं:
कहाँ
तब
कुल विचरणबिना किसी अपवाद के सभी कारकों (तथ्यात्मक विशेषताओं) के प्रभाव में अध्ययन किए गए (परिणामात्मक) विशेषता के परिवर्तन (भिन्नता) की विशेषता है। समस्या की स्थितियों के अनुसार यह 12.2 के बराबर है।
अनुभवजन्य सहसंबंध संबंधमापता है कि परिणामी विशेषता की कुल परिवर्तनशीलता का कितना हिस्सा अध्ययन किए जा रहे कारक के कारण होता है। यह कारक विचरण और कुल विचरण का अनुपात है:
हम अनुभवजन्य सहसंबंध संबंध को परिभाषित करते हैं:
विशेषताओं के बीच संबंध कमजोर और मजबूत (करीबी) हो सकते हैं। उनके मानदंडों का मूल्यांकन चैडॉक पैमाने पर किया जाता है:
0.1 0.3 0.5 0.7 0.9 हमारे उदाहरण में, गुण वाई और कारक एक्स के बीच संबंध कमजोर है
निर्धारण गुणांक.
आइए निर्धारण का गुणांक निर्धारित करें:
इस प्रकार, 0.67% भिन्नता लक्षणों के बीच अंतर के कारण है, और 99.37% अन्य कारकों के कारण है।
निष्कर्ष: इस मामले में, श्रमिकों का उत्पादन किसी विशिष्ट पाली में काम पर निर्भर नहीं करता है, यानी। उनकी श्रम उत्पादकता पर कार्य शिफ्ट का प्रभाव महत्वपूर्ण नहीं है और अन्य कारकों के कारण है।
उदाहरण संख्या 3. श्रमिकों के दो समूहों के लिए औसत मजदूरी के आंकड़ों और इसके मूल्य से वर्ग विचलन के आधार पर, भिन्नताओं को जोड़ने के नियम को लागू करके कुल भिन्नता ज्ञात करें:
समाधान:समूह के भीतर भिन्नताओं का औसत
हम अंतरसमूह विचरण को इस प्रकार परिभाषित करते हैं:
कुल विचरण होगा: 480 + 13824 = 14304
 .
.
इसके विपरीत, यदि एक गैर-नकारात्मक ae है। ऐसे कार्य करें  , तो इस पर एक बिल्कुल निरंतर संभाव्यता माप है जैसे कि यह इसका घनत्व है।
, तो इस पर एक बिल्कुल निरंतर संभाव्यता माप है जैसे कि यह इसका घनत्व है।
लेब्सेग इंटीग्रल में माप को बदलना:
 ,
,
कोई बोरेल फ़ंक्शन कहां है जो संभाव्यता माप के संबंध में एकीकृत है।
फैलाव, प्रकार और फैलाव के गुण फैलाव की अवधारणा
आंकड़ों में बिखरावअंकगणित माध्य से विशेषता वर्ग के व्यक्तिगत मूल्यों के मानक विचलन के रूप में पाया जाता है। प्रारंभिक डेटा के आधार पर, यह सरल और भारित विचरण सूत्रों का उपयोग करके निर्धारित किया जाता है:
1. सरल विचरण(असमूहीकृत डेटा के लिए) की गणना सूत्र का उपयोग करके की जाती है:
![]()
2. भारित विचरण (भिन्नता श्रृंखला के लिए):

जहां n आवृत्ति है (कारक X की पुनरावृत्ति)
भिन्नता खोजने का एक उदाहरण
यह पृष्ठ भिन्नता खोजने का एक मानक उदाहरण बताता है, आप इसे खोजने के लिए अन्य समस्याओं को भी देख सकते हैं
उदाहरण 1. समूह, समूह औसत, अंतरसमूह और कुल विचरण का निर्धारण
उदाहरण 2. समूहीकरण तालिका में विचरण और भिन्नता का गुणांक ज्ञात करना
उदाहरण 3. एक असतत श्रृंखला में भिन्नता ढूँढना
उदाहरण 4. निम्नलिखित डेटा 20 पत्राचार छात्रों के समूह के लिए उपलब्ध है। विशेषता के वितरण की एक अंतराल श्रृंखला का निर्माण करना, विशेषता के औसत मूल्य की गणना करना और उसके फैलाव का अध्ययन करना आवश्यक है

आइए एक अंतराल समूह बनाएं। आइए सूत्र का उपयोग करके अंतराल की सीमा निर्धारित करें:
![]()
जहां एक्स अधिकतम समूहीकरण विशेषता का अधिकतम मूल्य है; एक्स मिनट - समूहीकरण विशेषता का न्यूनतम मूल्य; n - अंतरालों की संख्या:
हम n=5 स्वीकार करते हैं। चरण है: h = (192 - 159)/5 = 6.6
आइए एक अंतराल समूह बनाएं

आगे की गणना के लिए, हम एक सहायक तालिका बनाएंगे:

X"i - अंतराल का मध्य। (उदाहरण के लिए, अंतराल 159 - 165.6 = 162.3 का मध्य)
हम भारित अंकगणितीय औसत सूत्र का उपयोग करके छात्रों की औसत ऊंचाई निर्धारित करते हैं:

आइए सूत्र का उपयोग करके विचरण निर्धारित करें:
सूत्र को इस प्रकार बदला जा सकता है:

इस सूत्र से यह निष्कर्ष निकलता है विचरण बराबर है विकल्पों के वर्गों के औसत और वर्ग तथा औसत के बीच का अंतर।
भिन्नता श्रृंखला में फैलावक्षणों की विधि का उपयोग करके समान अंतराल के साथ फैलाव की दूसरी संपत्ति (अंतराल के मूल्य से सभी विकल्पों को विभाजित करके) का उपयोग करके निम्नलिखित तरीके से गणना की जा सकती है। विचरण का निर्धारण, क्षणों की विधि का उपयोग करके गणना की गई, निम्नलिखित सूत्र का उपयोग करना कम श्रमसाध्य है:

जहां i अंतराल का मान है; ए एक पारंपरिक शून्य है, जिसके लिए उच्चतम आवृत्ति वाले अंतराल के मध्य का उपयोग करना सुविधाजनक है; m1 प्रथम क्रम क्षण का वर्ग है; एम2 - दूसरे क्रम का क्षण
वैकल्पिक गुण विचरण (यदि किसी सांख्यिकीय जनसंख्या में कोई विशेषता इस प्रकार बदलती है कि केवल दो परस्पर अनन्य विकल्प हैं, तो ऐसी परिवर्तनशीलता को वैकल्पिक कहा जाता है) की गणना सूत्र का उपयोग करके की जा सकती है:

इस विचरण सूत्र में q = 1-p प्रतिस्थापित करने पर, हमें प्राप्त होता है:

विचरण के प्रकार
कुल विचरणइस भिन्नता का कारण बनने वाले सभी कारकों के प्रभाव में संपूर्ण जनसंख्या में किसी विशेषता की भिन्नता को मापता है। यह x के समग्र माध्य मान से किसी विशेषता x के व्यक्तिगत मानों के विचलन के माध्य वर्ग के बराबर है और इसे सरल विचरण या भारित विचरण के रूप में परिभाषित किया जा सकता है।
समूह के भीतर भिन्नता यादृच्छिक भिन्नता की विशेषता है, अर्थात भिन्नता का वह भाग जो बेहिसाब कारकों के प्रभाव के कारण होता है और समूह का आधार बनाने वाले कारक-विशेषता पर निर्भर नहीं होता है। ऐसा फैलाव समूह के अंकगणितीय माध्य से समूह X के भीतर विशेषता के व्यक्तिगत मूल्यों के विचलन के माध्य वर्ग के बराबर है और इसकी गणना साधारण फैलाव या भारित फैलाव के रूप में की जा सकती है।
इस प्रकार, समूह के भीतर विचरण के उपायएक समूह के भीतर एक विशेषता की भिन्नता और सूत्र द्वारा निर्धारित की जाती है:

जहां xi समूह का औसत है; ni समूह में इकाइयों की संख्या है।
उदाहरण के लिए, किसी कार्यशाला में श्रम उत्पादकता के स्तर पर श्रमिकों की योग्यता के प्रभाव का अध्ययन करने के कार्य में इंट्राग्रुप भिन्नताएं निर्धारित की जानी चाहिए, जो सभी संभावित कारकों (उपकरण की तकनीकी स्थिति, उपलब्धता) के कारण प्रत्येक समूह में आउटपुट में भिन्नता दिखाती हैं। उपकरण और सामग्री, श्रमिकों की आयु, श्रम तीव्रता, आदि), योग्यता श्रेणी में अंतर को छोड़कर (एक समूह के भीतर सभी श्रमिकों की योग्यता समान होती है)।
समूह के भीतर भिन्नताओं का औसत यादृच्छिक भिन्नता को दर्शाता है, अर्थात, भिन्नता का वह हिस्सा जो समूहीकरण कारक के अपवाद के साथ अन्य सभी कारकों के प्रभाव में हुआ। इसकी गणना सूत्र का उपयोग करके की जाती है:

अंतरसमूह विचरणपरिणामी विशेषता की व्यवस्थित भिन्नता को दर्शाता है, जो समूह का आधार बनाने वाले कारक-विशेषता के प्रभाव के कारण होता है। यह समग्र माध्य से समूह माध्य के विचलन के माध्य वर्ग के बराबर है। अंतरसमूह विचरण की गणना सूत्र का उपयोग करके की जाती है:

आइए इसमें गणना करेंएमएसएक्सेलनमूना विचरण और मानक विचलन। यदि किसी यादृच्छिक चर का वितरण ज्ञात हो तो हम उसके प्रसरण की भी गणना करेंगे।
आइए पहले विचार करें फैलाव, तब मानक विचलन.
नमूना विचरण
नमूना विचरण (नमूना विचरण,नमूनाझगड़ा) के सापेक्ष सरणी में मूल्यों के प्रसार की विशेषता है।
सभी 3 सूत्र गणितीय रूप से समतुल्य हैं।
प्रथम सूत्र से यह स्पष्ट है कि नमूना विचरणसरणी में प्रत्येक मान के वर्ग विचलन का योग है औसत से, नमूना आकार माइनस 1 से विभाजित।
प्रसरण नमूने DISP() फ़ंक्शन का उपयोग किया जाता है, अंग्रेज़ी। नाम VAR, यानी वैरियन्स। संस्करण MS EXCEL 2010 से, इसके एनालॉग DISP.V(), अंग्रेजी का उपयोग करने की अनुशंसा की जाती है। नाम VARS, यानी नमूना विचरण। इसके अलावा, MS EXCEL 2010 के संस्करण से शुरू होकर, एक फ़ंक्शन DISP.Г(), अंग्रेजी है। नाम VARP, यानी जनसंख्या भिन्नता, जो गणना करती है फैलावके लिए जनसंख्या. पूरा अंतर हर में आता है: DISP.V() की तरह n-1 के बजाय, DISP.G() में हर में सिर्फ n है। MS EXCEL 2010 से पहले, VAR() फ़ंक्शन का उपयोग जनसंख्या के विचरण की गणना के लिए किया जाता था।
नमूना विचरण
=QUADROTCL(नमूना)/(गिनती(नमूना)-1)
=(योग(नमूना)-गिनती(नमूना)*औसत(नमूना)^2)/ (गिनती(नमूना)-1)- सामान्य सूत्र
=SUM((नमूना -औसत(नमूना))^2)/ (गिनती(नमूना)-1) –
नमूना विचरण 0 के बराबर है, केवल तभी जब सभी मान एक दूसरे के बराबर हों और, तदनुसार, बराबर हों औसत मूल्य. आमतौर पर, मूल्य जितना बड़ा होगा प्रसरण, सरणी में मानों का प्रसार जितना अधिक होगा।
नमूना विचरणएक बिंदु अनुमान है प्रसरणउस यादृच्छिक चर का वितरण जिससे इसे बनाया गया था नमूना. निर्माण के बारे में विश्वास अंतरालमूल्यांकन करते समय प्रसरणलेख में पढ़ा जा सकता है.
एक यादृच्छिक चर का प्रसरण
की गणना करना फैलावयादृच्छिक चर, आपको इसे जानना आवश्यक है।
के लिए प्रसरणयादृच्छिक चर X को अक्सर Var(X) से दर्शाया जाता है। फैलावमाध्य E(X) से विचलन के वर्ग के बराबर: Var(X)=E[(X-E(X)) 2 ]
फैलावसूत्र द्वारा गणना:

जहां x i वह मान है जो एक यादृच्छिक चर ले सकता है, और μ औसत मान है (), p(x) संभावना है कि यादृच्छिक चर मान x लेगा।
यदि एक यादृच्छिक चर है, तो फैलावसूत्र द्वारा गणना:

आयाम प्रसरणमूल मानों की माप की इकाई के वर्ग से मेल खाता है। उदाहरण के लिए, यदि नमूने में मान आंशिक वजन माप (किलो में) का प्रतिनिधित्व करते हैं, तो विचरण आयाम किलो 2 होगा। इसकी व्याख्या करना कठिन हो सकता है, इसलिए मूल्यों के प्रसार को चिह्नित करने के लिए, के वर्गमूल के बराबर मान प्रसरण – मानक विचलन.
कुछ गुण प्रसरण:
Var(X+a)=Var(X), जहां X एक यादृच्छिक चर है और a एक स्थिरांक है।
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*ई(एक्स)*ई(एक्स)+(ई(एक्स)) 2 =ई(एक्स 2)-(ई(एक्स)) 2
इस फैलाव गुण का उपयोग किया जाता है रैखिक प्रतिगमन के बारे में लेख.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), जहां X और Y यादृच्छिक चर हैं, Cov(X;Y) इन यादृच्छिक चर का सहप्रसरण है।
यदि यादृच्छिक चर स्वतंत्र हैं, तो वे सहप्रसरण 0 के बराबर है, और इसलिए Var(X+Y)=Var(X)+Var(Y). फैलाव के इस गुण का उपयोग व्युत्पत्ति में किया जाता है।
आइए हम दिखाते हैं कि स्वतंत्र मात्राओं के लिए Var(X-Y)=Var(X+Y). दरअसल, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 वार(वाई)= वार(एक्स)+वार(वाई)= वार(एक्स+वाई)। इस फैलाव गुण का उपयोग निर्माण के लिए किया जाता है।
नमूना मानक विचलन
नमूना मानक विचलनयह इस बात का माप है कि किसी नमूने में मान उनके सापेक्ष कितने व्यापक रूप से बिखरे हुए हैं।
ए-प्राथमिकता, मानक विचलनके वर्गमूल के बराबर प्रसरण:

मानक विचलनमें मूल्यों के परिमाण को ध्यान में नहीं रखता है नमूना, लेकिन केवल उनके आसपास मूल्यों के फैलाव की डिग्री औसत. इसे स्पष्ट करने के लिए, आइए एक उदाहरण दें।
आइए 2 नमूनों के लिए मानक विचलन की गणना करें: (1; 5; 9) और (1001; 1005; 1009)। दोनों मामलों में, s=4. यह स्पष्ट है कि सरणी मानों के मानक विचलन का अनुपात नमूनों के बीच महत्वपूर्ण रूप से भिन्न होता है। ऐसे मामलों के लिए इसका उपयोग किया जाता है भिन्नता का गुणांक(भिन्नता का गुणांक, सीवी) - अनुपात मानक विचलनऔसत तक अंकगणित, प्रतिशत के रूप में व्यक्त किया गया।
गणना के लिए MS EXCEL 2007 और पुराने संस्करणों में नमूना मानक विचलनफ़ंक्शन =STDEVAL() का उपयोग किया जाता है, अंग्रेजी। नाम STDEV, यानी मानक विचलन। MS EXCEL 2010 के संस्करण से, इसके एनालॉग =STDEV.B(), अंग्रेजी का उपयोग करने की अनुशंसा की जाती है। नाम STDEV.S, अर्थात्। नमूना मानक विचलन।
इसके अलावा, MS EXCEL 2010 के संस्करण से शुरू होकर, एक फ़ंक्शन STANDARDEV.G(), अंग्रेजी है। नाम STDEV.P, अर्थात्। जनसंख्या मानक विचलन, जो गणना करता है मानक विचलनके लिए जनसंख्या. पूरा अंतर हर में आता है: STANDARDEV.V() में n-1 के बजाय, STANDARDEVAL.G() में हर में सिर्फ n है।
मानक विचलननीचे दिए गए सूत्रों का उपयोग करके सीधे भी गणना की जा सकती है (उदाहरण फ़ाइल देखें)
=रूट(QUADROTCL(नमूना)/(गिनती(नमूना)-1))
=रूट((योग(नमूना)-गिनती(नमूना)*औसत(नमूना)^2)/(गिनती(नमूना)-1))
बिखराव के अन्य उपाय
SQUADROTCL() फ़ंक्शन गणना करता है उनके मूल्यों के वर्ग विचलन का योग औसत. यह फ़ंक्शन सूत्र के समान परिणाम देगा =DISP.G( नमूना)*जाँच करना( नमूना) , कहाँ नमूना- नमूना मानों की एक सरणी वाली श्रेणी का संदर्भ ()। QUADROCL() फ़ंक्शन में गणना सूत्र के अनुसार की जाती है:

SROTCL() फ़ंक्शन डेटा सेट के प्रसार का एक माप भी है। फ़ंक्शन SROTCL() मानों के विचलन के निरपेक्ष मानों के औसत की गणना करता है औसत. यह फ़ंक्शन सूत्र के समान परिणाम लौटाएगा =SUMPRODUCT(ABS(नमूना-औसत(नमूना)))/COUNT(नमूना), कहाँ नमूना- नमूना मानों की एक श्रृंखला वाली श्रेणी का एक लिंक।
फ़ंक्शन SROTCL () में गणना सूत्र के अनुसार की जाती है:

कदम
नमूना विचरण की गणना
-
नमूना मान रिकॉर्ड करें.ज्यादातर मामलों में, सांख्यिकीविदों के पास केवल विशिष्ट आबादी के नमूनों तक पहुंच होती है। उदाहरण के लिए, एक नियम के रूप में, सांख्यिकीविद् रूस में सभी कारों की समग्रता को बनाए रखने की लागत का विश्लेषण नहीं करते हैं - वे कई हजार कारों के यादृच्छिक नमूने का विश्लेषण करते हैं। ऐसा नमूना कार की औसत लागत निर्धारित करने में मदद करेगा, लेकिन, सबसे अधिक संभावना है, परिणामी मूल्य वास्तविक से बहुत दूर होगा।
- उदाहरण के लिए, आइए यादृच्छिक क्रम में 6 दिनों में एक कैफे में बेचे गए बन्स की संख्या का विश्लेषण करें। नमूना इस तरह दिखता है: 17, 15, 23, 7, 9, 13। यह एक नमूना है, जनसंख्या नहीं, क्योंकि हमारे पास कैफे के खुले रहने के प्रत्येक दिन बेचे गए बन्स का डेटा नहीं है।
- यदि आपको मूल्यों के नमूने के बजाय जनसंख्या दी गई है, तो अगले भाग पर जारी रखें।
-
नमूना विचरण की गणना के लिए एक सूत्र लिखें।फैलाव एक निश्चित मात्रा के मूल्यों के प्रसार का माप है। विचरण मान शून्य के जितना करीब होता है, मान उतने ही करीब एक साथ समूहीकृत होते हैं। मानों के नमूने के साथ काम करते समय, विचरण की गणना के लिए निम्नलिखित सूत्र का उपयोग करें:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- एक्स) 2 (\डिस्प्लेस्टाइल ^(2))] / (एन - 1)
- s 2 (\displaystyle s^(2))- यह फैलाव है. फैलाव को वर्ग इकाइयों में मापा जाता है।
- x i (\displaystyle x_(i))- नमूने में प्रत्येक मान.
- x i (\displaystyle x_(i))आपको x̅ घटाना होगा, उसका वर्ग करना होगा और फिर परिणाम जोड़ना होगा।
- x̅ – नमूना माध्य (नमूना माध्य)।
- n – नमूने में मानों की संख्या.
-
नमूना माध्य की गणना करें.इसे x̅ के रूप में दर्शाया जाता है। नमूना माध्य की गणना एक साधारण अंकगणितीय माध्य के रूप में की जाती है: नमूने में सभी मान जोड़ें, और फिर परिणाम को नमूने में मानों की संख्या से विभाजित करें।
- हमारे उदाहरण में, नमूने में मान जोड़ें: 15 + 17 + 23 + 7 + 9 + 13 = 84
अब परिणाम को नमूने में मानों की संख्या से विभाजित करें (हमारे उदाहरण में 6 हैं): 84 ÷ 6 = 14।
नमूना माध्य x̅ = 14. - नमूना माध्य वह केंद्रीय मान है जिसके चारों ओर नमूने में मान वितरित किए जाते हैं। यदि नमूना माध्य के चारों ओर नमूना क्लस्टर में मान हैं, तो विचरण छोटा है; अन्यथा भिन्नता बड़ी है.
- हमारे उदाहरण में, नमूने में मान जोड़ें: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
नमूने में प्रत्येक मान से नमूना माध्य घटाएँ।अब अंतर की गणना करें x i (\displaystyle x_(i))- x̅, कहाँ x i (\displaystyle x_(i))- नमूने में प्रत्येक मान. प्राप्त प्रत्येक परिणाम नमूना माध्य से किसी विशेष मान के विचलन की डिग्री को इंगित करता है, अर्थात, यह मान नमूना माध्य से कितनी दूर है।
- हमारे उदाहरण में:
x 1 (\displaystyle x_(1))- एक्स = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- एक्स = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - प्राप्त परिणामों की सत्यता की जांच करना आसान है, क्योंकि उनका योग शून्य के बराबर होना चाहिए। यह औसत की परिभाषा से संबंधित है, क्योंकि नकारात्मक मान (औसत से छोटे मान तक की दूरी) सकारात्मक मान (औसत से बड़े मान तक की दूरी) से पूरी तरह से ऑफसेट हो जाते हैं।
- हमारे उदाहरण में:
-
जैसा कि ऊपर बताया गया है, मतभेदों का योग x i (\displaystyle x_(i))- x̅ शून्य के बराबर होना चाहिए। इसका मतलब यह है कि औसत विचरण हमेशा शून्य होता है, जिससे किसी निश्चित मात्रा के मूल्यों के प्रसार के बारे में कोई पता नहीं चलता है। इस समस्या को हल करने के लिए, प्रत्येक अंतर का वर्ग करें x i (\displaystyle x_(i))- एक्स। इसके परिणामस्वरूप आपको केवल सकारात्मक संख्याएँ प्राप्त होंगी, जिनका योग कभी भी 0 नहीं होगा।
- हमारे उदाहरण में:
(x 1 (\displaystyle x_(1))- एक्स) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))- एक्स) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - आपको अंतर का वर्ग मिल गया - x̅) 2 (\डिस्प्लेस्टाइल ^(2))नमूने में प्रत्येक मान के लिए.
- हमारे उदाहरण में:
-
अंतरों के वर्गों का योग ज्ञात कीजिए।अर्थात्, सूत्र का वह भाग ज्ञात कीजिए जो इस प्रकार लिखा गया है: ∑[( x i (\displaystyle x_(i))- एक्स) 2 (\डिस्प्लेस्टाइल ^(2))]. यहां चिह्न Σ का अर्थ प्रत्येक मान के लिए वर्ग अंतरों का योग है x i (\displaystyle x_(i))नमूने में. आपको पहले से ही चुकता अंतर मिल गया है (x i (\displaystyle (x_(i))- एक्स) 2 (\डिस्प्लेस्टाइल ^(2))प्रत्येक मान के लिए x i (\displaystyle x_(i))नमूने में; अब बस इन वर्गों को जोड़ें।
- हमारे उदाहरण में: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
परिणाम को n - 1 से विभाजित करें, जहां n नमूने में मानों की संख्या है।कुछ समय पहले, नमूना विचरण की गणना करने के लिए, सांख्यिकीविदों ने परिणाम को केवल n से विभाजित किया था; इस मामले में आपको वर्गांकित प्रसरण का माध्य मिलेगा, जो किसी दिए गए नमूने के प्रसरण का वर्णन करने के लिए आदर्श है। लेकिन याद रखें कि कोई भी नमूना मूल्यों की आबादी का केवल एक छोटा सा हिस्सा है। यदि आप दूसरा नमूना लेते हैं और वही गणना करते हैं, तो आपको एक अलग परिणाम मिलेगा। जैसा कि यह पता चला है, n - 1 (सिर्फ n के बजाय) से विभाजित करने पर जनसंख्या भिन्नता का अधिक सटीक अनुमान मिलता है, जिसमें आपकी रुचि है। n-1 से विभाजन आम हो गया है, इसलिए इसे नमूना विचरण की गणना के सूत्र में शामिल किया गया है।
- हमारे उदाहरण में, नमूने में 6 मान शामिल हैं, अर्थात n = 6।
नमूना विचरण = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- हमारे उदाहरण में, नमूने में 6 मान शामिल हैं, अर्थात n = 6।
-
विचरण और मानक विचलन के बीच अंतर.ध्यान दें कि सूत्र में एक घातांक होता है, इसलिए फैलाव को विश्लेषण किए जा रहे मान की वर्ग इकाइयों में मापा जाता है। कभी-कभी ऐसे परिमाण को संचालित करना काफी कठिन होता है; ऐसे मामलों में, मानक विचलन का उपयोग करें, जो विचरण के वर्गमूल के बराबर है। इसीलिए नमूना विचरण को इस प्रकार दर्शाया गया है s 2 (\displaystyle s^(2)), और नमूने का मानक विचलन इस प्रकार है s (\डिस्प्लेस्टाइल s).
- हमारे उदाहरण में, नमूने का मानक विचलन है: s = √33.2 = 5.76।
जनसंख्या भिन्नता की गणना
-
मूल्यों के कुछ सेट का विश्लेषण करें.सेट में विचाराधीन मात्रा के सभी मान शामिल हैं। उदाहरण के लिए, यदि आप लेनिनग्राद क्षेत्र के निवासियों की आयु का अध्ययन कर रहे हैं, तो समग्रता में इस क्षेत्र के सभी निवासियों की आयु शामिल है। जनसंख्या के साथ काम करते समय, एक तालिका बनाने और उसमें जनसंख्या मान दर्ज करने की अनुशंसा की जाती है। निम्नलिखित उदाहरण पर विचार करें:
- एक निश्चित कमरे में 6 एक्वैरियम हैं। प्रत्येक एक्वेरियम में निम्नलिखित संख्या में मछलियाँ होती हैं:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- एक निश्चित कमरे में 6 एक्वैरियम हैं। प्रत्येक एक्वेरियम में निम्नलिखित संख्या में मछलियाँ होती हैं:
-
जनसंख्या विचरण की गणना के लिए एक सूत्र लिखिए।चूँकि जनसंख्या में एक निश्चित मात्रा के सभी मान शामिल होते हैं, नीचे दिया गया सूत्र आपको जनसंख्या विचरण का सटीक मान प्राप्त करने की अनुमति देता है। जनसंख्या भिन्नता को नमूना भिन्नता (जो केवल एक अनुमान है) से अलग करने के लिए, सांख्यिकीविद् विभिन्न चर का उपयोग करते हैं:
- σ 2 (\डिस्प्लेस्टाइल ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\डिस्प्लेस्टाइल ^(2)))/एन
- σ 2 (\डिस्प्लेस्टाइल ^(2))- जनसंख्या फैलाव ("सिग्मा वर्ग" के रूप में पढ़ें)। फैलाव को वर्ग इकाइयों में मापा जाता है।
- x i (\displaystyle x_(i))- प्रत्येक मान उसकी संपूर्णता में।
- Σ - योग चिह्न. अर्थात् प्रत्येक मान से x i (\displaystyle x_(i))आपको μ घटाना होगा, उसका वर्ग करना होगा और फिर परिणाम जोड़ना होगा।
- μ - जनसंख्या माध्य.
- n – जनसंख्या में मूल्यों की संख्या.
-
जनसंख्या माध्य की गणना करें.किसी जनसंख्या के साथ काम करते समय, इसका माध्य μ (mu) के रूप में दर्शाया जाता है। जनसंख्या माध्य की गणना एक साधारण अंकगणितीय माध्य के रूप में की जाती है: जनसंख्या में सभी मूल्यों को जोड़ें, और फिर परिणाम को जनसंख्या में मूल्यों की संख्या से विभाजित करें।
- ध्यान रखें कि औसत की गणना हमेशा अंकगणितीय माध्य के रूप में नहीं की जाती है।
- हमारे उदाहरण में, जनसंख्या का अर्थ है: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
जनसंख्या के प्रत्येक मान से जनसंख्या माध्य घटाएँ।अंतर मान शून्य के जितना करीब होगा, विशिष्ट मान जनसंख्या माध्य के उतना ही करीब होगा। जनसंख्या में प्रत्येक मान और उसके माध्य के बीच अंतर ज्ञात करें, और आपको मूल्यों के वितरण का पहला अंदाजा मिल जाएगा।
- हमारे उदाहरण में:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- हमारे उदाहरण में:
-
प्राप्त प्रत्येक परिणाम का वर्ग करें।अंतर मान सकारात्मक और नकारात्मक दोनों होंगे; यदि इन मानों को एक संख्या रेखा पर आलेखित किया जाता है, तो वे जनसंख्या माध्य के दायीं और बायीं ओर स्थित होंगे। यह विचरण की गणना के लिए अच्छा नहीं है क्योंकि धनात्मक और ऋणात्मक संख्याएँ एक दूसरे को रद्द कर देती हैं। इसलिए विशेष रूप से सकारात्मक संख्याएँ प्राप्त करने के लिए प्रत्येक अंतर का वर्ग करें।
- हमारे उदाहरण में:
(x i (\displaystyle x_(i)) - μ) 2 (\डिस्प्लेस्टाइल ^(2))प्रत्येक जनसंख्या मान के लिए (i = 1 से i = 6 तक):
(-5,5)2 (\डिस्प्लेस्टाइल ^(2)) = 30,25
(-5,5)2 (\डिस्प्लेस्टाइल ^(2)), कहाँ x n (\displaystyle x_(n))- जनसंख्या में अंतिम मान. - प्राप्त परिणामों के औसत मूल्य की गणना करने के लिए, आपको उनका योग ज्ञात करना होगा और इसे n से विभाजित करना होगा:(( x 1 (\displaystyle x_(1)) - μ) 2 (\डिस्प्लेस्टाइल ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\डिस्प्लेस्टाइल ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\डिस्प्लेस्टाइल ^(2)))/एन
- आइए अब वेरिएबल्स का उपयोग करके उपरोक्त स्पष्टीकरण लिखें: (∑( x i (\displaystyle x_(i)) - μ) 2 (\डिस्प्लेस्टाइल ^(2))) / n और जनसंख्या विचरण की गणना के लिए एक सूत्र प्राप्त करें।
- हमारे उदाहरण में:
 (1रेटिंग, औसतन: 5,00 5 में से)
(1रेटिंग, औसतन: 5,00 5 में से)