Rastgele bir değişkenin dağılımı. Ayrı bir rasgele değişkenin dağılımı. Standart sapma
nerede σ 2 j, j -inci grubun grup içi varyansıdır.
Gruplandırılmamış veriler için artık dağılım yaklaşım doğruluğunun bir ölçüsüdür, yani regresyon çizgisinin orijinal verilere yaklaşımı: 
burada y(t), trend denklemine göre tahmindir; y t – ilk dinamik serisi; n nokta sayısıdır; p, regresyon denkleminin katsayılarının sayısıdır (açıklayıcı değişkenlerin sayısı).
Bu örnekte denir tarafsız varyans tahmini.
Örnek 1. Bir derneğin üç işletmesindeki işçilerin tarife kategorilerine göre dağılımı, aşağıdaki verilerle karakterize edilir:
| İşçi maaşı kategorisi | İşletmedeki çalışan sayısı | ||
| işletme 1 | işletme 2 | işletme 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Tanımlamak:
1. her işletme için dağılım (grup içi dağılım);
2. grup içi dağılımların ortalaması;
3. gruplar arası dağılım;
4. toplam varyans.
Çözüm.
Problemi çözmeye geçmeden önce hangi özelliğin etkili hangisinin faktöriyel olduğunu bulmak gerekir. Ele alınan örnekte, etkin özellik “Tarife kategorisi” ve faktör özelliği “işletmenin numarası (adı)” dır.
Ardından, grup ortalamasını ve grup içi varyansları hesaplamanın gerekli olduğu üç grubumuz (işletmelerimiz) var:

| Şirket | grup ortalaması, | grup içi varyans, |
| 1 | 4 | 1,8 |
Grup içi varyansların ortalaması ( artık dağılım) aşağıdaki formülle hesaplanır:

nerede hesaplayabilirsiniz:

veya:
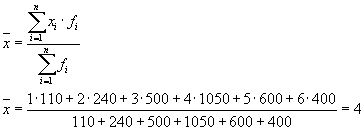
Daha sonra:
Toplam dağılım şuna eşit olacaktır: s 2 \u003d 1.6 + 0 \u003d 1.6.
Toplam varyans, aşağıdaki iki formülden biri kullanılarak da hesaplanabilir:

Pratik problemleri çözerken, genellikle yalnızca iki alternatif değer alan bir işaretle uğraşmak gerekir. Bu durumda, bir özelliğin belirli bir değerinin ağırlığından değil, toplam içindeki payından bahsediyorlar. İncelenen özelliği taşıyan popülasyon birimlerinin oranı " ile gösterilirse R"ve sahip olmamak - aracılığıyla" Q”, ardından dağılım aşağıdaki formülle hesaplanabilir:
s 2 = p×q
Örnek 2. Tugaydaki altı işçinin gelişimine ilişkin verilere göre, gruplar arası varyansı belirleyin ve toplam varyans 12.2 ise iş vardiyasının işgücü verimliliği üzerindeki etkisini değerlendirin.
| Çalışan tugay sayısı | Çalışma çıkışı, adet. | |
| ilk vardiyada | 2. vardiyada | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Çözüm. İlk veri
| X | f1 | f2 | f 3 | f4 | f5 | f6 | Toplam |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Toplam | 31 | 33 | 37 | 37 | 40 | 38 |
Daha sonra, grup ortalamasını ve grup içi varyansları hesaplamak için gerekli olan 6 grubumuz var.
1. Her grubun ortalama değerlerini bulun.
2. Her grubun ortalama karesini bulun.
Hesaplamanın sonuçlarını bir tabloda özetliyoruz:
| Grup numarası | Grup ortalaması | grup içi varyans |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. grup içi varyans gruplandırmanın altında yatan faktör hariç, tüm faktörlerin etkisi altında grup içinde çalışılan (sonuçta ortaya çıkan) özelliğin değişimini (varyasyonunu) karakterize eder:
Grup içi dağılımların ortalamasını aşağıdaki formülü kullanarak hesaplıyoruz:
4. Gruplar arası varyans gruplamanın altında yatan bir faktörün (faktöriyel özellik) etkisi altında incelenen (sonuçta ortaya çıkan) özelliğin değişimini (varyasyonunu) karakterize eder.
Gruplar arası dağılım şu şekilde tanımlanır:
Nerede
Daha sonra
Toplam varyans istisnasız tüm faktörlerin (faktöriyel özellikler) etkisi altında incelenen (sonuçta ortaya çıkan) özelliğin değişimini (varyasyonunu) karakterize eder. Sorunun durumuna göre, 12.2'ye eşittir.
Ampirik korelasyon ilişkisi elde edilen özelliğin toplam dalgalanmasının ne kadarının çalışılan faktörden kaynaklandığını ölçer. Bu, faktöriyel varyansın toplam varyansa oranıdır:
Ampirik korelasyon ilişkisini belirliyoruz:
Özellikler arasındaki ilişkiler zayıf veya güçlü (yakın) olabilir. Kriterleri Chaddock ölçeğine göre değerlendirilir:
0,1 0,3 0,5 0,7 0,9 Örneğimizde, Y faktörü X özelliği arasındaki ilişki zayıf
Belirleme katsayısı.
Belirleme katsayısını tanımlayalım:
Dolayısıyla, varyasyonun %0,67'si özellikler arasındaki farklılıklardan, %99,37'si ise diğer faktörlerden kaynaklanmaktadır.
Çözüm: Bu durumda, işçilerin çıktısı belirli bir vardiyadaki çalışmaya bağlı değildir, yani; iş vardiyasının işgücü verimliliği üzerindeki etkisi önemli değildir ve diğer faktörlerden kaynaklanmaktadır.
Örnek 3. İki işçi grubu için ortalama ücret ve değerinden sapmaların karesi ile ilgili verilere dayanarak, varyans toplama kuralını uygulayarak toplam varyansı bulun:
Çözüm:Grup içi varyansların ortalaması
Gruplar arası dağılım şu şekilde tanımlanır:
Toplam varyans şöyle olacaktır: 480 + 13824 = 14304
 .
.
Tersine, if negatif olmayan bir a.e'dir. öyle bir fonksiyon ki  , o zaman yoğunluğu olan üzerinde kesinlikle sürekli bir olasılık ölçüsü vardır.
, o zaman yoğunluğu olan üzerinde kesinlikle sürekli bir olasılık ölçüsü vardır.
Lebesgue integralinde ölçü değişikliği:
 ,
,
olasılık ölçüsüne göre integrallenebilen herhangi bir Borel fonksiyonudur.
Dispersiyon, dispersiyon türleri ve özellikleri Dispersiyon kavramı
İstatistiklerde dağılımözelliğin bireysel değerlerinin aritmetik ortalamadan karesinin standart sapması olarak bulunur. İlk verilere bağlı olarak, basit ve ağırlıklı varyans formülleriyle belirlenir:
1. basit varyans(gruplanmamış veriler için) aşağıdaki formülle hesaplanır:
![]()
2. Ağırlıklı varyans (bir varyasyon serisi için):

nerede n - frekans (tekrarlanabilirlik faktörü X)
Varyansı bulma örneği
Bu sayfa, varyansı bulmanın standart bir örneğini açıklar, onu bulmak için diğer görevlere de bakabilirsiniz.
Örnek 1. Grup, grup ortalaması, gruplar arası ve toplam varyansın belirlenmesi
Örnek 2. Bir gruplama tablosunda varyansı ve varyasyon katsayısını bulma
Örnek 3. Ayrık bir seride varyansı bulma
Örnek 4. 20 yazışmalı öğrenci grubu için aşağıdaki verilere sahibiz. Özellik dağılımının bir aralık serisini oluşturmak, özelliğin ortalama değerini hesaplamak ve varyansını incelemek gerekir.

Bir aralık gruplaması oluşturalım. Aralık aralığını aşağıdaki formülle belirleyelim:
![]()
burada Xmax, gruplama özelliğinin maksimum değeridir; X min, gruplama özelliğinin minimum değeridir; n, aralık sayısıdır:
n=5 kabul ediyoruz. Adım: h \u003d (192 - 159) / 5 \u003d 6.6
Aralıklı gruplama yapalım

Daha fazla hesaplama için yardımcı bir tablo oluşturacağız:

X "i - aralığın ortası. (örneğin, 159 - 165.6 \u003d 162.3 aralığının ortası)
Öğrencilerin ortalama büyümesi, aritmetik ağırlıklı ortalama formülü ile belirlenir:

Dağılımı aşağıdaki formüle göre belirleriz:
Formül şu şekilde dönüştürülebilir:

Bu formülden şu çıkar varyans seçeneklerin karelerinin ortalaması ile kare ve ortalama arasındaki fark.
Varyasyon serisindeki varyans moment yöntemine göre eşit aralıklarla, ikinci dağılım özelliği kullanılarak (tüm seçenekleri aralığın değerine bölerek) aşağıdaki şekilde hesaplanabilir. varyansın tanımı, aşağıdaki formüle göre momentler yöntemiyle hesaplandığında daha az zaman alır:

burada i, aralığın değeridir; A - aralığın ortasını en yüksek frekansla kullanmak için uygun olan koşullu sıfır; m1, birinci dereceden momentin karesidir; m2 - ikinci dereceden an
Özellik farkı (istatistiksel popülasyonda öznitelik, birbirini dışlayan yalnızca iki seçenek olacak şekilde değişirse, bu değişkenliğe alternatif denir) aşağıdaki formülle hesaplanabilir:

Bu dağılım formülünde q = 1-p yerine koyarak şunu elde ederiz:

dağılım türleri
Toplam varyans Bir özelliğin, bu varyasyona neden olan tüm faktörlerin etkisi altında bir bütün olarak tüm popülasyondaki varyasyonunu ölçer. x niteliğinin bireysel değerlerinin toplam ortalama x değerinden sapmalarının ortalama karesine eşittir ve basit varyans veya ağırlıklı varyans olarak tanımlanabilir.
grup içi varyans rastgele varyasyonu karakterize eder, yani açıklanmayan faktörlerin etkisinden kaynaklanan ve gruplamanın altında yatan işaret faktörüne bağlı olmayan varyasyonun bir kısmı. Bu varyans, X grubu içindeki özelliğin bireysel değerlerinin grubun aritmetik ortalamasından sapmalarının ortalama karesine eşittir ve basit bir varyans veya ağırlıklı bir varyans olarak hesaplanabilir.
Böylece, grup içi varyans ölçüleri Bir özelliğin bir grup içindeki varyasyonu ve aşağıdaki formülle belirlenir:

nerede xi - grup ortalaması; ni gruptaki birim sayısıdır.
Örneğin, bir atölyede işçilerin niteliklerinin işgücü üretkenliği düzeyi üzerindeki etkisini inceleme görevinde belirlenmesi gereken grup içi varyanslar, tüm olası faktörlerin (ekipmanın teknik durumu, araç ve gereçlerin mevcudiyeti, işçilerin yaşı, iş yoğunluğu vb.), yeterlilik kategorisindeki farklılıklar hariç (grup içinde, tüm işçiler aynı vasıflara sahiptir).
Grup içi varyansların ortalaması, rasgele varyasyonu, yani varyasyonun, gruplama faktörü hariç diğer tüm faktörlerin etkisi altında meydana gelen kısmını yansıtır. Aşağıdaki formülle hesaplanır:

Gruplar arası varyans gruplamanın altında yatan özellik faktörünün etkisinden kaynaklanan, ortaya çıkan özelliğin sistematik varyasyonunu karakterize eder. Grup ortalamalarının genel ortalamadan sapmalarının ortalama karesine eşittir. Gruplar arası varyans aşağıdaki formülle hesaplanır:

içinde hesaplayalımHANIMEXCELörneğin varyansı ve standart sapması. Dağılımı biliniyorsa, rastgele bir değişkenin varyansını da hesaplarız.
İlk önce düşünün dağılım, Daha sonra standart sapma.
Örnek varyans
Örnek varyans (örneklem varyansı,örnekvaryans) dizideki değerlerin göre dağılımını karakterize eder.
3 formülün tümü matematiksel olarak eşdeğerdir.
İlk formülden görülebileceği gibi örneklem varyansı dizideki her değerin kare sapmalarının toplamıdır ortalamadanörneklem büyüklüğü eksi 1'e bölünür.
dağılım örnekler DISP() işlevi kullanılır, eng. VAR'ın adı, yani Varyans. MS EXCEL 2010'dan bu yana, DISP.V() , eng. VARS adı, yani Örnek Varyans. Ek olarak, MS EXCEL 2010 sürümünden başlayarak, bir DISP.G () işlevi vardır, eng. VARP adı, yani hesaplayan Popülasyon VARYANS'ı dağılımİçin nüfus. Tüm fark paydada ortaya çıkar: DISP.V() gibi n-1 yerine, paydada DISP.G() sadece n vardır. MS EXCEL 2010'dan önce, popülasyon varyansını hesaplamak için VARP() işlevi kullanılıyordu.
Örnek varyans
=KARE(Örnek)/(SAYI(Örnek)-1)
=(TOPLAM(Örnek)-SAYI(Örnek)*ORTALAMA(Örnek)^2)/ (SAYI(Örnek)-1)- olağan formül
=TOPLA((Örnek -ORTALAMA(Örnek))^2)/ (SAYI(Örnek)-1) –
Örnek varyans yalnızca tüm değerler birbirine eşitse ve buna göre eşitse 0'a eşittir ortalama değer. Genellikle, değer ne kadar büyükse dağılım, dizideki değerlerin yayılması o kadar büyük olur.
Örnek varyans bir nokta tahminidir dağılım rastgele değişkenin dağılımı örnek. Bina hakkında güvenilirlik aralığı değerlendirirken dağılım makalede okunabilir.
Rastgele bir değişkenin varyansı
Hesaplamak dağılım rastgele değişken, onu bilmeniz gerekir.
İçin dağılım rasgele değişken X genellikle Var(X) gösterimini kullanır. Dağılım ortalamadan sapmanın karesine eşittir E(X): Var(X)=E[(X-E(X)) 2 ]
dağılım formülle hesaplanır:

burada x i rasgele değişkenin alabileceği değer ve μ ortalama değerdir (), р(x), rasgele değişkenin x değerini alma olasılığıdır.
Rastgele değişken varsa, o zaman dağılım formülle hesaplanır:

Boyut dağılım orijinal değerlerin ölçü biriminin karesine karşılık gelir. Örneğin, numunedeki değerler parçanın ağırlığının (kg cinsinden) ölçümleriyse, o zaman varyansın boyutu kg 2 olur. Bunu yorumlamak zor olabilir, bu nedenle, değerlerin dağılımını karakterize etmek için, kareköküne eşit bir değer dağılım – standart sapma.
bazı özellikler dağılım:
Var(X+a)=Var(X), burada X rastgele bir değişkendir ve a bir sabittir.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Bu dağılım özelliği, doğrusal regresyon hakkında makale.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), burada X ve Y rastgele değişkenlerdir, Cov(X;Y), bu rastgele değişkenlerin kovaryansıdır.
Rastgele değişkenler bağımsız ise, o zaman onların kovaryans 0'dır ve dolayısıyla Var(X+Y)=Var(X)+Var(Y). Varyansın bu özelliği çıktıda kullanılır.
Bağımsız nicelikler için Var(X-Y)=Var(X+Y) olduğunu gösterelim. Nitekim Var(X-Y)= Var(XY)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X) + (- 1) 2 Var (Y) \u003d Var (X) + Var (Y) \u003d Var (X + Y). Varyansın bu özelliği grafiği çizmek için kullanılır.
Numune standart sapması
Numune standart sapmasıörneklemdeki değerlerin .
A-rahip, standart sapma kareköküne eşittir dağılım:

Standart sapma içindeki değerlerin büyüklüğünü dikkate almaz. örnekleme, ancak yalnızca etraflarındaki değerlerin saçılma derecesi orta. Bunu açıklamak için bir örnek verelim.
2 örnek için standart sapmayı hesaplayalım: (1; 5; 9) ve (1001; 1005; 1009). Her iki durumda da s=4. Standart sapmanın dizinin değerlerine oranının örnekler için önemli ölçüde farklı olduğu açıktır. Bu gibi durumlarda, kullanın varyasyon katsayısı(Değişim Katsayısı, CV) - oran standart sapma ortalamaya aritmetik, yüzde olarak ifade edilir.
Hesaplama için MS EXCEL 2007 ve önceki sürümlerde Numune standart sapması=STDEV() işlevi kullanılır, tur. STDEV adı, yani standart sapma. MS EXCEL 2010'dan bu yana, analog = STDEV.B () , tur kullanılması önerilir. adı STDEV.S, yani Numune standart sapması.
Ek olarak, MS EXCEL 2010 sürümünden başlayarak, bir STDEV.G () işlevi vardır, eng. STDEV.P adı, yani Hesaplayan Nüfus STandart Sapması standart sapmaİçin nüfus. Tüm fark paydada ortaya çıkıyor: STDEV.V() gibi n-1 yerine, STDEV.G()'nin paydasında sadece n var.
Standart sapma doğrudan aşağıdaki formüllerden de hesaplanabilir (örnek dosyaya bakın)
=KAREKÖK(SQUADROTIV(Örnek)/(SAYI(Örnek)-1))
=KAREKÖK((TOPLAM(Örnek)-SAYI(Örnek)*ORTALAMA(Örnek)^2)/(SAYI(Örnek)-1))
Diğer dağılım önlemleri
SQUADRIVE() işlevi şununla hesaplar: değerlerin umm kare sapmaları orta. Bu işlev, =VAR.G( formülüyle aynı sonucu döndürür. Örnek)*KONTROL ETMEK( Örnek) , Nerede Örnek- bir dizi örnek değer () içeren bir aralığa referans. QUADROTIV() işlevindeki hesaplamalar aşağıdaki formüle göre yapılır:

SROOT() işlevi ayrıca bir veri kümesinin dağılımının bir ölçüsüdür. SIROTL() işlevi, değerlerin sapmalarının mutlak değerlerinin ortalamasını hesaplar. orta. Bu işlev, formülle aynı sonucu döndürür =SUMPRODUCT(MUTLAK(Örnek-ORTALAMA(Örnek)))/SAYI(Örnek), Nerede Örnek- bir dizi örnek değer içeren bir aralığa referans.
SROOTKL () işlevindeki hesaplamalar aşağıdaki formüle göre yapılır:

Adımlar
Örnek Varyans Hesaplaması
-
Örnek değerleri kaydedin.Çoğu durumda, istatistikçiler için yalnızca belirli popülasyonların örnekleri mevcuttur. Örneğin, kural olarak, istatistikçiler Rusya'daki tüm arabaların nüfusunu korumanın maliyetini analiz etmezler - birkaç bin arabanın rastgele bir örneğini analiz ederler. Böyle bir örnek, araba başına ortalama maliyetin belirlenmesine yardımcı olacaktır, ancak büyük olasılıkla, ortaya çıkan değer gerçek değerden uzak olacaktır.
- Örneğin bir kafede 6 günde satılan çörek sayısını rastgele sırayla inceleyelim. Örnek şu şekildedir: 17, 15, 23, 7, 9, 13. Bu bir nüfus değil, bir örnektir, çünkü kafenin açık olduğu her gün için satılan çörekler hakkında verimiz yoktur.
- Size bir değer örneği değil de bir popülasyon verilirse, bir sonraki bölüme geçin.
-
Örnek varyansı hesaplamak için formülü yazın. Dağılım, bazı miktarların değerlerinin yayılmasının bir ölçüsüdür. Dağılım değeri sıfıra ne kadar yakınsa, değerler o kadar birbirine yakın gruplanır. Bir değer örneğiyle çalışırken, varyansı hesaplamak için aşağıdaki formülü kullanın:
- s 2 (\displaystyle s^(2)) = ∑[(x ben (\displaystyle x_(i))-X) 2 (\görüntü stili ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) dağılımdır. Dağılım, kare birimlerle ölçülür.
- x ben (\displaystyle x_(i))- örnekteki her değer.
- x ben (\displaystyle x_(i)) x̅'yi çıkarmanız, karesini almanız ve ardından sonuçları eklemeniz gerekir.
- x̅ – örnek ortalama (örnek ortalama).
- n, örnekteki değerlerin sayısıdır.
-
Örnek ortalamayı hesaplayın. x̅ olarak gösterilir. Numune ortalaması, normal aritmetik ortalama gibi hesaplanır: numunedeki tüm değerleri toplayın ve ardından sonucu numunedeki değer sayısına bölün.
- Örneğimizde örnekteki değerleri toplayın: 15 + 17 + 23 + 7 + 9 + 13 = 84
Şimdi sonucu örnekteki değer sayısına bölün (bizim örneğimizde 6 vardır): 84 ÷ 6 = 14.
Örnek ortalama x̅ = 14. - Örnek ortalama, örnekteki değerlerin dağıldığı merkezi değerdir. Örnek ortalama etrafındaki örnek kümedeki değerler ise, varyans küçüktür; aksi takdirde, dağılım büyüktür.
- Örneğimizde örnekteki değerleri toplayın: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Numunedeki her değerden numune ortalamasını çıkarın.Şimdi farkı hesapla x ben (\displaystyle x_(i))- x̅, nerede x ben (\displaystyle x_(i))- örnekteki her değer. Elde edilen her sonuç, belirli bir değerin örneklem ortalamasından ne ölçüde saptığını, yani bu değerin örneklem ortalamasından ne kadar uzak olduğunu gösterir.
- Örneğimizde:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\görüntü stili x_(2))- x̅ = 15 - 14 = 1
x 3 (\görüntü stili x_(3))- x̅ = 23 - 14 = 9
x 4 (\görüntü stili x_(4))- x̅ = 7 - 14 = -7
x 5 (\görüntü stili x_(5))- x̅ = 9 - 14 = -5
x 6 (\görüntü stili x_(6))- x̅ = 13 - 14 = -1 - Elde edilen sonuçların doğruluğunu doğrulamak kolaydır, çünkü toplamlarının sıfıra eşit olması gerekir. Bu, ortalama değerin belirlenmesi ile ilgilidir, çünkü negatif değerler (ortalama değerden daha küçük değerlere olan mesafeler) pozitif değerlerle (ortalama değerden daha büyük değerlere olan mesafeler) tamamen dengelenir.
- Örneğimizde:
-
Yukarıda belirtildiği gibi, farklılıkların toplamı x ben (\displaystyle x_(i))- x̅ sıfıra eşit olmalıdır. Bu, ortalama varyansın her zaman sıfır olduğu anlamına gelir, bu da bir niceliğin değerlerinin yayılması hakkında hiçbir fikir vermez. Bu sorunu çözmek için her bir farkın karesini alın x ben (\displaystyle x_(i))- X. Bu, yalnızca toplandığında asla 0'a ulaşmayacak olan pozitif sayılar elde etmenize neden olacaktır.
- Örneğimizde:
(x 1 (\displaystyle x_(1))-X) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-X) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Farkın karesini buldunuz - x̅) 2 (\görüntü stili ^(2))Örnekteki her değer için.
- Örneğimizde:
-
Kare farkların toplamını hesaplayın. Yani formülün şu şekilde yazılan kısmını bulun: ∑[( x ben (\displaystyle x_(i))-X) 2 (\görüntü stili ^(2))]. Burada Σ işareti, her değer için kare farklarının toplamı anlamına gelir x ben (\displaystyle x_(i))örnekte Kare farkları zaten buldunuz (x ben (\displaystyle (x_(i))-X) 2 (\görüntü stili ^(2)) her değer için x ben (\displaystyle x_(i))örnekte; şimdi sadece bu kareleri ekleyin.
- Örneğimizde: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Sonucu n - 1'e bölün, burada n, örnekteki değerlerin sayısıdır. Bir süre önce, örneklem varyansını hesaplamak için istatistikçiler sonucu basitçe n'ye bölerdi; bu durumda, belirli bir örneğin varyansını açıklamak için ideal olan varyansın karesinin ortalamasını alırsınız. Ancak, herhangi bir örneğin genel değerler popülasyonunun yalnızca küçük bir parçası olduğunu unutmayın. Farklı bir numune alıp aynı hesaplamaları yaparsanız farklı bir sonuç elde edersiniz. Görünen o ki, n - 1'e bölmek (yalnızca n'den ziyade), nüfus varyansının daha iyi bir tahminini veriyor, peşinde olduğunuz şey de bu. n - 1'e bölmek olağan hale geldi, bu nedenle örneklem varyansının hesaplanması için formüle dahil edildi.
- Örneğimizde, örnek 6 değer içerir, yani n = 6.
Örnek varyans = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- Örneğimizde, örnek 6 değer içerir, yani n = 6.
-
Varyans ve standart sapma arasındaki fark. Formülün bir üs içerdiğine dikkat edin, bu nedenle varyans, analiz edilen değerin kare birimlerinde ölçülür. Bazen böyle bir değeri çalıştırmak oldukça zordur; bu gibi durumlarda, varyansın kareköküne eşit olan standart sapma kullanılır. Bu nedenle örneklem varyansı şu şekilde gösterilir: s 2 (\displaystyle s^(2)) ve örnek standart sapması olarak s (\displaystyles).
- Örneğimizde, numune standart sapması: s = √33,2 = 5,76.
Nüfus varyansı hesaplaması
-
Bazı değer kümelerini analiz edin. Set, dikkate alınan miktarın tüm değerlerini içerir. Örneğin, Leningrad bölgesi sakinlerinin yaşını inceliyorsanız, nüfus bu bölgenin tüm sakinlerinin yaşını içerir. Bir agrega ile çalışma durumunda, bir tablo oluşturulması ve agrega değerlerinin içine girilmesi önerilir. Aşağıdaki örneği göz önünde bulundurun:
- Belirli bir odada 6 adet akvaryum bulunmaktadır. Her akvaryum aşağıdaki sayıda balık içerir:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- Belirli bir odada 6 adet akvaryum bulunmaktadır. Her akvaryum aşağıdaki sayıda balık içerir:
-
Popülasyon varyansını hesaplamak için formülü yazın. Popülasyon belirli bir miktarın tüm değerlerini içerdiğinden, aşağıdaki formül popülasyonun varyansının tam değerini elde etmenizi sağlar. Nüfus varyansını (yalnızca bir tahmin olan) örneklem varyansından ayırt etmek için istatistikçiler çeşitli değişkenler kullanır:
- σ 2 (\görüntü stili ^(2)) = (∑(x ben (\displaystyle x_(i)) - μ) 2 (\görüntü stili ^(2))) / N
- σ 2 (\görüntü stili ^(2))- nüfus varyansı ("sigma kare" olarak okunur). Dağılım, kare birimlerle ölçülür.
- x ben (\displaystyle x_(i))- toplamdaki her bir değer.
- Σ toplamın işaretidir. Yani her bir değer için x ben (\displaystyle x_(i))μ çıkarın, karesini alın ve ardından sonuçları ekleyin.
- μ popülasyon ortalamasıdır.
- n, genel popülasyondaki değerlerin sayısıdır.
-
Nüfus ortalamasını hesaplayın. Genel popülasyonla çalışırken, ortalama değeri μ (mu) olarak gösterilir. Popülasyon ortalaması, olağan aritmetik ortalama olarak hesaplanır: popülasyondaki tüm değerleri toplayın ve ardından sonucu popülasyondaki değer sayısına bölün.
- Ortalamaların her zaman aritmetik ortalama olarak hesaplanmadığını unutmayın.
- Örneğimizde, popülasyon şu anlama gelir: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Popülasyondaki her bir değerden popülasyon ortalamasını çıkarın. Fark değeri sıfıra ne kadar yakınsa, özel değer popülasyon ortalamasına o kadar yakındır. Popülasyondaki her bir değer ile ortalaması arasındaki farkı bulun ve değerlerin dağılımına ilk kez bakın.
- Örneğimizde:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\görüntü stili x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\görüntü stili x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\görüntü stili x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\görüntü stili x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\görüntü stili x_(6))- μ = 18 - 10,5 = 7,5
- Örneğimizde:
-
Elde ettiğiniz her sonucun karesini alın. Fark değerleri hem pozitif hem de negatif olacaktır; bu değerleri bir sayı doğrusuna koyarsanız, o zaman popülasyonun sağına ve soluna yalan söyleyeceklerdir. Pozitif ve negatif sayılar birbirini götürdüğü için bu, varyansı hesaplamak için iyi değildir. Bu nedenle, yalnızca pozitif sayılar elde etmek için her bir farkın karesini alın.
- Örneğimizde:
(x ben (\displaystyle x_(i)) - μ) 2 (\görüntü stili ^(2)) her popülasyon değeri için (i = 1'den i = 6'ya):
(-5,5)2 (\görüntü stili ^(2)) = 30,25
(-5,5)2 (\görüntü stili ^(2)), Nerede x n (\displaystyle x_(n)) popülasyondaki son değerdir. - Elde edilen sonuçların ortalama değerini hesaplamak için toplamlarını bulmanız ve n'ye bölmeniz gerekir: (( x 1 (\displaystyle x_(1)) - μ) 2 (\görüntü stili ^(2)) + (x 2 (\görüntü stili x_(2)) - μ) 2 (\görüntü stili ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\görüntü stili ^(2))) / N
- Şimdi yukarıdaki açıklamayı değişkenleri kullanarak yazalım: (∑( x ben (\displaystyle x_(i)) - μ) 2 (\görüntü stili ^(2))) / n ve popülasyon varyansını hesaplamak için bir formül elde edin.
- Örneğimizde:
 (1 derecelendirmeler, ortalama olarak: 5,00 5 üzerinden)
(1 derecelendirmeler, ortalama olarak: 5,00 5 üzerinden)