Varyansı bulma örneği. Ayrık bir rastgele değişkenin beklentisi
Varyans Bir rastgele değişkenin (saçılımı), bir rastgele değişkenin matematiksel beklentisinden sapmasının karesinin matematiksel beklentisidir:
Varyansı hesaplamak için biraz değiştirilmiş bir formül kullanabilirsiniz.
Çünkü M(X), 2 ve  – sabit değerler. Böylece,
– sabit değerler. Böylece,
4.2.2. Dispersiyon özellikleri
Mülk 1. Sabit bir değerin varyansı sıfırdır. Gerçekten de tanım gereği
Mülk 2. Sabit faktör, karesi alınarak dağılım işaretinden çıkarılabilir.
Kanıt
ortalanmış Rastgele değişken, rastgele bir değişkenin matematiksel beklentisinden sapmasıdır:

Merkezi bir niceliğin dönüşüme uygun iki özelliği vardır:
Mülk 3. Rastgele değişkenler X ve e bağımsızlar o zaman
Kanıt. Haydi belirtelim  . Daha sonra.
. Daha sonra.
İkinci dönemde rastgele değişkenlerin bağımsızlığı ve merkezli rastgele değişkenlerin özelliklerinden dolayı
Örnek 4.5. Eğer A Ve B– sabitler, o zamanD (AX+B)=
D(AX)+D(B)= .
.
4.2.3. Standart sapma
Rastgele bir değişkenin yayılmasının bir özelliği olarak dağılımın bir dezavantajı vardır. Örneğin, X– ölçüm hatasının bir boyutu vardır AA, o zaman dağılımın boyutu vardır  . Bu nedenle sıklıkla başka bir dağılım özelliği kullanmayı tercih ederler: standart sapma
varyansın kareköküne eşit olan
. Bu nedenle sıklıkla başka bir dağılım özelliği kullanmayı tercih ederler: standart sapma
varyansın kareköküne eşit olan

Standart sapma, rastgele değişkenin kendisi ile aynı boyuta sahiptir.
Örnek 4.6. Bağımsız bir deneme tasarımında bir olayın meydana gelme sayısındaki varyans
Üretilmiş N bağımsız denemeler ve her denemede bir olayın meydana gelme olasılığı R. Daha önce olduğu gibi olayın gerçekleşme sayısını ifade edelim. X olayın bireysel deneylerde meydana gelme sayısına göre:
Deneyler bağımsız olduğundan deneylerle ilişkili rastgele değişkenler  bağımsız. Ve bağımsızlık nedeniyle
bağımsız. Ve bağımsızlık nedeniyle  sahibiz
sahibiz
Ancak rastgele değişkenlerin her birinin bir dağılım yasası vardır (örnek 3.2)
|
| ||

Ve  (örnek 4.4). Bu nedenle, varyansın tanımı gereği:
(örnek 4.4). Bu nedenle, varyansın tanımı gereği:
Nerede Q=1- P.
Sonuç olarak elimizde  ,
,
Bir olayın meydana gelme sayısının standart sapması N bağımsız deneyler eşit  .
.
4.3. Rastgele değişkenlerin momentleri
Halihazırda dikkate alınanlara ek olarak, rastgele değişkenlerin başka birçok sayısal özelliği vardır.
Başlangıç anı
k X
( ) matematiksel beklenti olarak adlandırılır k Bu rastgele değişkenin -inci kuvveti.
) matematiksel beklenti olarak adlandırılır k Bu rastgele değişkenin -inci kuvveti.
Merkezi an k inci dereceli rastgele değişken X matematiksel beklenti denir k karşılık gelen merkezlenmiş miktarın -inci kuvveti.

Birinci dereceden merkezi momentin her zaman sıfıra eşit olduğunu, ikinci dereceden merkezi momentin dağılıma eşit olduğunu görmek kolaydır, çünkü .
Üçüncü dereceden merkezi moment, bir rastgele değişkenin dağılımının asimetrisi hakkında fikir verir. İkinciden daha yüksek sıra anları nispeten nadiren kullanılır, bu nedenle kendimizi yalnızca kavramların kendisiyle sınırlayacağız.
4.4. Dağıtım yasalarını bulma örnekleri
Rastgele değişkenlerin dağılım yasalarını ve bunların sayısal özelliklerini bulma örneklerini ele alalım.
Örnek 4.7.
Her atışta isabet olasılığı 0,4 ise, hedefe üç atışla isabet sayısının dağılımı için bir yasa çizin. İntegral fonksiyonunu bulun F(X) ayrık bir rastgele değişkenin elde edilen dağılımı için X ve bunun bir grafiğini çizin. Beklenen değeri bulun M(X)
, varyans D(X)
ve standart sapma  (X) rastgele değişken X.
(X) rastgele değişken X.
Çözüm
1) Ayrık rastgele değişken X– üç atışla hedefe yapılan isabet sayısı – dört değer alabilir: 0, 1, 2, 3 . Her birini kabul etme olasılığı Bernoulli formülü kullanılarak bulunur: N=3,P=0,4,Q=1- P=0,6 ve M=0, 1, 2, 3:
Olası değerlerin olasılıklarını alalım X:;
Rastgele bir değişkenin istenen dağılım yasasını oluşturalım X:
Kontrol: 0,216+0,432+0,288+0,064=1.
Ortaya çıkan rastgele değişkenin bir dağıtım poligonunu oluşturalım X. Bunu yapmak için dikdörtgen koordinat sisteminde (0; 0,216), (1; 0,432), (2; 0,288), (3; 0,064) noktalarını işaretliyoruz. Bu noktaları düz çizgi parçalarıyla birleştirelim, ortaya çıkan kesikli çizgi istenen dağıtım poligonudur (Şekil 4.1).

2) Eğer x  0, o zaman F(X)=0. Aslında sıfırdan küçük değerler için değer X kabul etmiyor. Bu nedenle herkes için X
0, o zaman F(X)=0. Aslında sıfırdan küçük değerler için değer X kabul etmiyor. Bu nedenle herkes için X 0, tanımı kullanarak F(X), alıyoruz F(X)=P(X<
X)
=0 (imkansız bir olayın olasılığı olarak).
0, tanımı kullanarak F(X), alıyoruz F(X)=P(X<
X)
=0 (imkansız bir olayın olasılığı olarak).
0 ise  , O F(X)
=0,216. Gerçekten de bu durumda F(X)=P(X<
X)
=
=P(-
, O F(X)
=0,216. Gerçekten de bu durumda F(X)=P(X<
X)
=
=P(-
 <
X
<
X  0)+
P(0<
X<
X)
=0,216+0=0,216.
0)+
P(0<
X<
X)
=0,216+0=0,216.
Örneğin şunu alırsak: X=0,2 ise F(0,2)=P(X<0,2) . Ancak bir olayın gerçekleşme olasılığı X<0,2 равна 0,216, так как случайная величинаX yalnızca bir durumda 0,2'den küçük bir değer alır, yani 0 0,216 olasılıkla.
Eğer 1  , O
, O
Gerçekten mi, X 0,216 olasılıkla 0 değerini, 0,432 olasılıkla 1 değerini alabilir; dolayısıyla bu anlamlardan biri, hangisi olursa olsun, X(uyumsuz olayların olasılıklarının eklenmesi teoremine göre) 0,648 olasılıkla kabul edebilir.
2 ise  o zaman benzer şekilde tartışarak şunu elde ederiz: F(X)=0,216+0,432 + + 0,288=0,936. Aslında, örneğin, X=3. Daha sonra F(3)=P(X<3)
bir olayın olasılığını ifade eder X<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF(X).
o zaman benzer şekilde tartışarak şunu elde ederiz: F(X)=0,216+0,432 + + 0,288=0,936. Aslında, örneğin, X=3. Daha sonra F(3)=P(X<3)
bir olayın olasılığını ifade eder X<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF(X).
Eğer X>3 ise F(X)=0,216+0,432+0,288+0,064=1. Gerçekten de olay X güvenilirdir ve olasılığı bire eşittir ve X>3 – imkansız. Hesaba katıldığında
güvenilirdir ve olasılığı bire eşittir ve X>3 – imkansız. Hesaba katıldığında
F(X)=P(X<
X)
=P(X  3)
+
P(3<
X<
X)
belirtilen sonucu elde ederiz.
3)
+
P(3<
X<
X)
belirtilen sonucu elde ederiz.
Böylece, X rastgele değişkeninin gerekli integral dağılım fonksiyonu elde edilir:
F(X)
=

grafiği Şekil 2'de gösterilmektedir. 4.2.

3) Ayrık bir rastgele değişkenin matematiksel beklentisi, tüm olası değerlerin çarpımlarının toplamına eşittir X olasılıklarına göre:
M(X)=0=1,2.
Yani ortalama olarak üç atışla hedefe bir vuruş yapılır.
Varyans, varyansın tanımından hesaplanabilir D(X)=
M(X-
M(X))
 veya formülü kullanın D(X)=
M(X
veya formülü kullanın D(X)=
M(X  , bu da hedefe daha hızlı ulaşmanızı sağlar.
, bu da hedefe daha hızlı ulaşmanızı sağlar.
Rastgele bir değişkenin dağılım yasasını yazalım X  :
:
Matematiksel beklentiyi bulalım X :
:
M(X  )
= 04
)
= 04 = 2,16.
= 2,16.
Gerekli varyansı hesaplayalım:
D(X)
=
M(X  )
– (M(X))
)
– (M(X))
 = 2,16 – (1,2)
= 2,16 – (1,2) = 0,72.
= 0,72.
Formülü kullanarak standart sapmayı buluyoruz
 (X)
=
(X)
=
 = 0,848.
= 0,848.
Aralık ( M-
 ;
M+
;
M+
 ) = (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – rastgele değişkenin en olası değerlerinin aralığı X 1 ve 2 değerlerini içerir.
) = (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – rastgele değişkenin en olası değerlerinin aralığı X 1 ve 2 değerlerini içerir.
Örnek 4.8.
Sürekli bir rastgele değişkenin diferansiyel dağılım fonksiyonu (yoğunluk fonksiyonu) verildiğinde X:
 F(X)
=
F(X)
=
1) Sabit parametreyi belirleyin A.
2) İntegral fonksiyonunu bulun F(X) .
3) Fonksiyon grafikleri oluşturun F(X) Ve F(X) .
4) Olasılığı iki şekilde bulun P(0,5<
X  1,5)
Ve P(1,5<
X<3,5)
.
1,5)
Ve P(1,5<
X<3,5)
.
5). Beklenen değeri bulun M(X), varyans D(X) ve standart sapma  rastgele değişken X.
rastgele değişken X.
Çözüm
1) Özelliğe göre diferansiyel fonksiyon F(X)
koşulu sağlamalıdır  .
.
Bu fonksiyon için uygun olmayan integrali hesaplayalım F(X) :

Bu sonucu eşitliğin sol tarafında yerine koyarsak şunu elde ederiz: A=1. Durumunda F(X)
parametreyi değiştir A 1'e: 

2) Bulmak F(X) formülü kullanalım
 .
.
eğer x  , O
, O  , buradan,
, buradan, 
Eğer 1  O
O
Eğer x>2 ise
Yani gerekli integral fonksiyonu F(X) şu forma sahiptir:

3) Fonksiyonların grafiklerini oluşturalım F(X) Ve F(X) (Şekil 4.3 ve 4.4).


4) Rastgele bir değişkenin belirli bir aralığa düşme olasılığı (A,B)
formülle hesaplanır  Eğer fonksiyon biliniyorsa F(X),
ve formüle göre P(A
<
X
<
B)
=
F(B)
–
F(A),
eğer fonksiyon biliniyorsa
F(X).
Eğer fonksiyon biliniyorsa F(X),
ve formüle göre P(A
<
X
<
B)
=
F(B)
–
F(A),
eğer fonksiyon biliniyorsa
F(X).
Bulacağız  iki formül kullanarak sonuçları karşılaştırın. Koşullara göre a=0,5;B=1,5;
işlev F(X)
1. maddede belirtilmiştir). Bu nedenle formüle göre gerekli olasılık şuna eşittir:
iki formül kullanarak sonuçları karşılaştırın. Koşullara göre a=0,5;B=1,5;
işlev F(X)
1. maddede belirtilmiştir). Bu nedenle formüle göre gerekli olasılık şuna eşittir:
Aynı olasılık, adım 2)'de elde edilen artış yoluyla formül b) kullanılarak hesaplanabilir. integral fonksiyonu F(X) bu aralıkta:
Çünkü F(0,5)=0.
Benzer şekilde buluyoruz 
Çünkü F(3,5)=1.
5) Matematiksel beklentiyi bulmak M(X) formülü kullanalım  İşlev F(X)
1. noktanın çözümünde verildiğinde), (1,2] aralığı dışında sıfıra eşittir:
İşlev F(X)
1. noktanın çözümünde verildiğinde), (1,2] aralığı dışında sıfıra eşittir:

 Sürekli bir rastgele değişkenin varyansı D(X) eşitlikle belirlenir
Sürekli bir rastgele değişkenin varyansı D(X) eşitlikle belirlenir
 veya eşdeğer eşitlik
veya eşdeğer eşitlik

 .
.
İçin  bulma D(X)
Son formülü kullanalım ve mümkün olan tüm değerleri dikkate alalım. F(X)
(1,2] aralığına aittir:
bulma D(X)
Son formülü kullanalım ve mümkün olan tüm değerleri dikkate alalım. F(X)
(1,2] aralığına aittir:
Standart sapma  =
= =0,276.
=0,276.
Rastgele bir değişkenin en olası değerlerinin aralığı X eşittir
(M-  ,A+
,A+  )
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
)
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
Olasılık teorisi, yalnızca yüksek öğretim kurumlarının öğrencileri tarafından incelenen özel bir matematik dalıdır. Hesaplamaları ve formülleri sever misiniz? Ayrık bir rastgele değişkenin normal dağılımı, topluluk entropisi, matematiksel beklenti ve dağılımı hakkında bilgi sahibi olma ihtimalinden korkmuyor musunuz? O zaman bu konu sizin için çok ilginç olacak. Bu bilim dalının en önemli temel kavramlarından birkaçını tanıyalım.
Temelleri hatırlayalım
Olasılık teorisinin en basit kavramlarını hatırlasanız bile yazının ilk paragraflarını ihmal etmeyin. Mesele şu ki, temelleri net bir şekilde anlamadan aşağıda tartışılan formüllerle çalışamayacaksınız.
Yani bazı rastgele olaylar meydana gelir, bazı deneyler olur. Yaptığımız eylemlerin sonucunda çeşitli sonuçlar elde edebiliriz; bunlardan bazıları daha sık, bazıları ise daha az sıklıkla meydana gelir. Bir olayın olasılığı, bir türden gerçekten elde edilen sonuçların sayısının, olası sonuçların toplam sayısına oranıdır. Yalnızca bu kavramın klasik tanımını bilerek, sürekli rastgele değişkenlerin matematiksel beklentisini ve dağılımını incelemeye başlayabilirsiniz.
Ortalama
Okula döndüğünüzde matematik dersleri sırasında aritmetik ortalamayla çalışmaya başladınız. Bu kavram olasılık teorisinde yaygın olarak kullanılmaktadır ve bu nedenle göz ardı edilemez. Şu anda bizim için asıl önemli olan, bir rastgele değişkenin matematiksel beklentisi ve dağılımına ilişkin formüllerde bununla karşılaşacak olmamızdır.

Bir dizi sayımız var ve aritmetik ortalamayı bulmak istiyoruz. Bizden istenen tek şey, mevcut olan her şeyi toplamak ve dizideki öğe sayısına bölmektir. 1'den 9'a kadar sayımız olsun. Elementlerin toplamı 45 olacak, bu değeri 9'a böleceğiz. Cevap: - 5.
Dağılım
Bilimsel açıdan dağılım, bir özelliğin elde edilen değerlerinin aritmetik ortalamadan sapmalarının ortalama karesidir. Tek büyük Latin harfi D ile gösterilir. Hesaplamak için ne gereklidir? Dizinin her elemanı için mevcut sayı ile aritmetik ortalama arasındaki farkı hesaplayıp karesini alıyoruz. Düşündüğümüz olaya ilişkin sonuçların olabileceği kadar değer olacaktır. Daha sonra, alınan her şeyi özetliyoruz ve dizideki öğe sayısına bölüyoruz. Beş olası sonucumuz varsa, o zaman beşe bölün.

Dispersiyonun problem çözerken kullanılabilmesi için hatırlanması gereken özellikleri de vardır. Örneğin, bir rastgele değişken X kat artırıldığında, varyans X kare kat artar (yani X*X). Hiçbir zaman sıfırdan küçük değildir ve değerlerin eşit miktarlarda yukarı veya aşağı kaydırılmasına bağlı değildir. Ayrıca bağımsız denemelerde toplamın varyansı, varyansların toplamına eşittir.
Şimdi kesinlikle ayrık bir rastgele değişkenin varyansı ve matematiksel beklenti örneklerini dikkate almamız gerekiyor.
Diyelim ki 21 deney yaptık ve 7 farklı sonuç elde ettik. Her birini sırasıyla 1, 2, 2, 3, 4, 4 ve 5 kez gözlemledik. Varyans neye eşit olacak?
Öncelikle aritmetik ortalamayı hesaplayalım: elemanların toplamı elbette 21'dir. Bunu 7'ye bölerek 3 elde ederiz. Şimdi orijinal dizideki her sayıdan 3 çıkarın, her değerin karesini alın ve sonuçları toplayın. Sonuç 12. Şimdi tek yapmamız gereken sayıyı element sayısına bölmek ve öyle görünüyor ki hepsi bu. Ama bir sorun var! Bunu tartışalım.
Deney sayısına bağımlılık
Varyansı hesaplarken paydanın iki sayıdan birini içerebileceği ortaya çıktı: N veya N-1. Burada N, gerçekleştirilen deneylerin sayısı veya dizideki öğelerin sayısıdır (ki bu aslında aynı şeydir). Bu neye bağlıdır?

Test sayısı yüzlerce olarak ölçülürse paydaya N koymalıyız, birim olarak ise N-1. Bilim adamları sınırı oldukça sembolik olarak çizmeye karar verdiler: bugün 30 sayısını geçiyor. 30'dan az deney yaptıysak, miktarı N-1'e, daha fazlaysa N'ye böleceğiz.
Görev
Varyans problemini ve matematiksel beklentiyi çözme örneğimize dönelim. N veya N-1'e bölünmesi gereken bir ara sayı olan 12'ye sahibiz. 21 deney yaptığımız için (30'dan az) ikinci seçeneği seçeceğiz. Yani cevap şu: varyans 12/2 = 2.
Beklenen değer
Bu yazıda dikkate almamız gereken ikinci kavrama geçelim. Matematiksel beklenti, tüm olası sonuçların karşılık gelen olasılıklarla çarpılmasının sonucudur. Elde edilen değerin ve varyansın hesaplanması sonucunun, içinde kaç sonuç dikkate alınırsa alınsın, tüm problem için yalnızca bir kez elde edildiğini anlamak önemlidir.

Matematiksel beklentinin formülü oldukça basittir: Sonucu alırız, olasılığıyla çarparız, aynısını ikinci, üçüncü sonuç için ekleriz vb. Bu kavramla ilgili her şeyin hesaplanması zor değildir. Örneğin beklenen değerlerin toplamı, toplamın beklenen değerine eşittir. Aynı durum iş için de geçerlidir. Olasılık teorisindeki her nicelik bu kadar basit işlemleri gerçekleştirmenize izin vermez. Problemi ele alalım ve incelediğimiz iki kavramın anlamını aynı anda hesaplayalım. Üstelik teori dikkatimizi dağıtmıştı; şimdi pratik yapma zamanı.
Bir örnek daha
50 deneme yaptık ve farklı yüzdelerde görünen 10 tür sonuç (0'dan 9'a kadar sayılar) elde ettik. Bunlar sırasıyla: %2, %10, %4, %14, %2, %18, %6, %16, %10, %18. Olasılıkları elde etmek için yüzde değerlerini 100'e bölmeniz gerektiğini hatırlayın. Böylece 0,02 elde ederiz; 0.1 vb. Rastgele bir değişkenin varyansı ve matematiksel beklenti problemini çözmeye yönelik bir örnek sunalım.
Aritmetik ortalamayı ilkokuldan hatırladığımız formülü kullanarak hesaplıyoruz: 50/10 = 5.
Şimdi saymayı kolaylaştırmak için olasılıkları “parçalar halinde” sonuç sayısına dönüştürelim. 1, 5, 2, 7, 1, 9, 3, 8, 5 ve 9 elde ederiz. Elde edilen her değerden aritmetik ortalamayı çıkarırız ve ardından elde edilen sonuçların her birinin karesini alırız. Örnek olarak ilk öğeyi kullanarak bunu nasıl yapacağınızı görün: 1 - 5 = (-4). Sonraki: (-4) * (-4) = 16. Diğer değerler için bu işlemleri kendiniz yapın. Her şeyi doğru yaptıysanız, hepsini topladıktan sonra 90 elde edeceksiniz.

90'ı N'ye bölerek varyansı ve beklenen değeri hesaplamaya devam edelim. Neden N-1 yerine N'yi seçiyoruz? Doğru, çünkü yapılan deney sayısı 30'u geçiyor. Yani: 90/10 = 9. Varyansı bulduk. Farklı bir numara alırsanız umutsuzluğa kapılmayın. Büyük ihtimalle hesaplamalarda basit bir hata yaptınız. Yazdıklarınızı bir kez daha kontrol edin, muhtemelen her şey yerine oturacaktır.
Son olarak matematiksel beklenti formülünü hatırlayın. Tüm hesaplamaları vermeyeceğiz, yalnızca gerekli tüm prosedürleri tamamladıktan sonra kontrol edebileceğiniz bir cevap yazacağız. Beklenen değer 5,48 olacaktır. İlk elemanları örnek olarak kullanarak yalnızca işlemlerin nasıl gerçekleştirileceğini hatırlayalım: 0*0,02 + 1*0,1... vb. Gördüğünüz gibi, sonuç değerini olasılığıyla çarpıyoruz.
Sapma
Dağılım ve matematiksel beklentiyle yakından ilişkili bir diğer kavram ise standart sapmadır. Latin harfleri sd veya Yunanca küçük harf “sigma” ile gösterilir. Bu kavram, değerlerin merkezi özellikten ortalama ne kadar saptığını gösterir. Değerini bulmak için varyansın karekökünü hesaplamanız gerekir.

Normal bir dağılım grafiği çiziyorsanız ve sapmanın karesini doğrudan üzerinde görmek istiyorsanız, bu birkaç aşamada yapılabilir. Görüntünün yarısını modun soluna veya sağına alın (merkezi değer), elde edilen rakamların alanları eşit olacak şekilde yatay eksene dik bir çizin. Dağılımın ortası ile yatay eksen üzerindeki sonuç projeksiyonu arasındaki bölümün boyutu standart sapmayı temsil edecektir.
Yazılım
Formüllerin açıklamalarından ve sunulan örneklerden de görülebileceği gibi, varyansın ve matematiksel beklentinin hesaplanması aritmetik açıdan en basit prosedür değildir. Zaman kaybetmemek için yükseköğretim kurumlarında kullanılan programı kullanmak mantıklıdır - buna "R" denir. İstatistik ve olasılık teorisinden birçok kavrama ilişkin değerleri hesaplamanıza olanak sağlayan işlevlere sahiptir.
Örneğin, değerlerin bir vektörünü belirtirsiniz. Bu şu şekilde yapılır: vektör<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
Nihayet
Dağılım ve matematiksel beklenti olmadan gelecekte herhangi bir şeyi hesaplamak zordur. Üniversitelerdeki derslerin ana derslerinde, konuyu incelemenin ilk aylarında zaten tartışılıyorlar. Tam olarak bu basit kavramların anlaşılmaması ve hesaplanamaması nedeniyle birçok öğrenci programda hemen geri kalmaya başlıyor ve daha sonra oturumun sonunda kötü notlar alıyor ve bu da onları burslardan mahrum bırakıyor.
Bu makalede sunulanlara benzer görevleri çözerek en az bir hafta, günde yarım saat pratik yapın. Daha sonra, olasılık teorisindeki herhangi bir testte, gereksiz ipuçları ve hileler olmadan örneklerle baş edebileceksiniz.
Gruplandırılmış veriler için artık varyans- grup içi varyansların ortalaması:Burada σ 2 j, j'inci grubun grup içi varyansıdır.
Gruplandırılmamış veriler için artık varyans– yaklaşıklık doğruluğunun ölçüsü, yani regresyon çizgisinin orijinal verilere yaklaşımı: 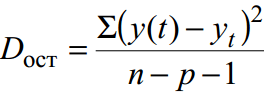
burada y(t) – trend denklemine göre tahmin; y t – başlangıç dinamikleri serisi; n – puan sayısı; p – regresyon denklemi katsayılarının sayısı (açıklayıcı değişkenlerin sayısı).
Bu örnekte buna denir tarafsız varyans tahmincisi.
Örnek No.1. Bir derneğin üç işletmesindeki işçilerin tarife kategorilerine göre dağılımı aşağıdaki verilerle karakterize edilir:
| İşçi tarife kategorisi | İşletmedeki işçi sayısı | ||
| işletme 1 | işletme 2 | işletme 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Tanımlamak:
1. her işletme için farklılık (grup içi farklılıklar);
2. grup içi varyansların ortalaması;
3. gruplar arası dağılım;
4. toplam varyans.
Çözüm.
Sorunu çözmeye başlamadan önce hangi özelliğin etkili, hangisinin faktöriyel olduğunu bulmak gerekir. Söz konusu örnekte, sonuç niteliği “Tarife kategorisi”, faktör niteliği ise “İşletmenin numarası (adı)”dır.
Daha sonra grup ortalamasını ve grup içi varyansları hesaplamanın gerekli olduğu üç grubumuz (işletmelerimiz) var:

| Şirket | Grup ortalaması, | Grup içi varyans, |
| 1 | 4 | 1,8 |
Grup içi varyansların ortalaması ( artık varyans) aşağıdaki formül kullanılarak hesaplanacaktır:

nerede hesaplayabilirsiniz:

veya:
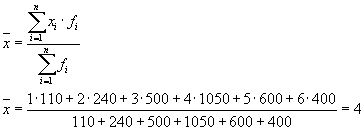
Daha sonra:
Toplam varyans şuna eşit olacaktır: s 2 = 1,6 + 0 = 1,6.
Toplam varyans aşağıdaki iki formülden biri kullanılarak da hesaplanabilir:

Pratik problemleri çözerken, genellikle yalnızca iki alternatif değer alan bir özellik ile uğraşmak gerekir. Bu durumda bir özelliğin belirli bir değerinin ağırlığından değil, bütünlük içindeki payından bahsediyoruz. İncelenen özelliğe sahip nüfus birimlerinin oranı “ ile gösteriliyorsa R"ve sahip olmayanlar - aracılığıyla " Q", o zaman varyans aşağıdaki formül kullanılarak hesaplanabilir:
s 2 = p×q
Örnek No.2. Bir ekipteki altı işçinin üretim verilerine dayanarak, gruplar arası varyansı belirleyin ve toplam varyansın 12,2 olması durumunda iş vardiyasının işgücü verimliliği üzerindeki etkisini değerlendirin.
| Ekip çalışanı no. | İşçi çıktısı, adet. | |
| ilk vardiyada | ikinci vardiyada | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Çözüm. İlk veri
| X | f1 | f2 | f3 | f4 | f5 | f6 | Toplam |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Toplam | 31 | 33 | 37 | 37 | 40 | 38 |
Daha sonra grup ortalamasını ve grup içi varyansları hesaplamanın gerekli olduğu 6 grubumuz var.
1. Her grubun ortalama değerlerini bulun.
2. Her grubun ortalama karesini bulun.
Hesaplama sonuçlarını bir tabloda özetleyelim:
| Grup numarası | Grup ortalaması | Grup içi varyans |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Grup içi varyans gruplandırmanın altında yatan faktör hariç, üzerindeki tüm faktörlerin etkisi altında bir grup içinde incelenen (sonuçsal) özelliğin değişimini (varyasyonunu) karakterize eder:
Grup içi varyansların ortalaması aşağıdaki formül kullanılarak hesaplanacaktır:
4. Gruplararası varyans Grubun temelini oluşturan bir faktörün (faktöriyel özellik) etkisi altında çalışılan (sonuçsal) özelliğin değişimini (varyasyonunu) karakterize eder.
Gruplar arası varyansı şu şekilde tanımlarız:
Nerede
Daha sonra
Toplam varyansİstisnasız tüm faktörlerin (faktöriyel özellikler) etkisi altında incelenen (sonuçsal) özelliğin değişimini (varyasyonunu) karakterize eder. Problemin koşullarına göre 12,2'ye eşittir.
Ampirik korelasyon ilişkisi Sonuçta ortaya çıkan özelliğin toplam değişkenliğinin ne kadarının incelenen faktörden kaynaklandığını ölçer. Faktör varyansının toplam varyansa oranı:
Ampirik korelasyon ilişkisini tanımlıyoruz:
Karakteristikler arasındaki bağlantılar zayıf ve güçlü (yakın) olabilir. Kriterleri Chaddock ölçeğine göre değerlendirilir:
0,1 0,3 0,5 0,7 0,9 Örneğimizde Y özelliği ile X faktörü arasındaki ilişki zayıf
Belirleme katsayısı.
Belirleme katsayısını belirleyelim:
Yani varyasyonun %0,67'si özellikler arasındaki farklardan, %99,37'si ise diğer faktörlerden kaynaklanmaktadır.
Çözüm: bu durumda, işçilerin çıktısı belirli bir vardiyadaki çalışmaya bağlı değildir; İş vardiyasının işgücü üretkenliği üzerindeki etkisi önemli değildir ve başka faktörlerden kaynaklanmaktadır.
Örnek No. 3. Ortalama ücretler ve iki işçi grubu için değerinden sapmaların kareleri ile ilgili verilere dayanarak, varyansları toplama kuralını uygulayarak toplam varyansı bulun:
Çözüm:Grup içi varyansların ortalaması
Gruplar arası varyansı şu şekilde tanımlarız:
Toplam varyans şöyle olacaktır: 480 + 13824 = 14304
İstatistiklerde dağılım karakteristiğin bireysel değerlerinin karesi olarak bulunur. Başlangıç verilerine bağlı olarak basit ve ağırlıklı varyans formülleri kullanılarak belirlenir:
1. (gruplandırılmamış veriler için) aşağıdaki formül kullanılarak hesaplanır:
2. Ağırlıklı varyans (varyasyon serileri için):
 burada n frekanstır (X faktörünün tekrarlanabilirliği)
burada n frekanstır (X faktörünün tekrarlanabilirliği)
Varyansı bulma örneği
Bu sayfada varyans bulmanın standart bir örneği açıklanmaktadır; bunu bulmak için diğer problemlere de bakabilirsiniz.
Örnek 1. Aşağıdaki veriler 20 yazışma öğrencisinden oluşan bir grup için mevcuttur. Karakteristiğin dağılımına ilişkin bir aralık serisi oluşturmak, özelliğin ortalama değerini hesaplamak ve dağılımını incelemek gerekir.
 Bir aralık gruplaması oluşturalım. Aşağıdaki formülü kullanarak aralığın aralığını belirleyelim:
Bir aralık gruplaması oluşturalım. Aşağıdaki formülü kullanarak aralığın aralığını belirleyelim:
![]() burada Xmax, gruplandırma karakteristiğinin maksimum değeridir;
burada Xmax, gruplandırma karakteristiğinin maksimum değeridir;
X min – gruplandırma karakteristiğinin minimum değeri;
n – aralık sayısı:
n=5 kabul ediyoruz. Adım: h = (192 - 159)/ 5 = 6,6
Bir aralık gruplaması oluşturalım
 Daha fazla hesaplama için yardımcı bir tablo oluşturacağız:
Daha fazla hesaplama için yardımcı bir tablo oluşturacağız:
 X'i aralığın ortasıdır. (örneğin 159 – 165,6 aralığının ortası = 162,3)
X'i aralığın ortasıdır. (örneğin 159 – 165,6 aralığının ortası = 162,3)
Ağırlıklı aritmetik ortalama formülünü kullanarak öğrencilerin ortalama boyunu belirleriz:
 Aşağıdaki formülü kullanarak varyansı belirleyelim:
Aşağıdaki formülü kullanarak varyansı belirleyelim:
Dispersiyon formülü aşağıdaki gibi dönüştürülebilir:

Bu formülden şu sonuç çıkıyor varyans eşittir seçeneklerin karelerinin ortalaması ile kare ve ortalama arasındaki fark.
Varyasyon serisindeki dağılım Momentler yöntemini kullanarak eşit aralıklarla, ikinci dağılım özelliği kullanılarak (tüm seçeneklerin aralığın değerine bölünmesiyle) aşağıdaki şekilde hesaplanabilir. Varyansın belirlenmesi Momentler yöntemi kullanılarak hesaplanan aşağıdaki formülü kullanmak daha az zahmetlidir:

burada i aralığın değeridir;
A, aralığın ortasını en yüksek frekansla kullanmanın uygun olduğu geleneksel bir sıfırdır;
m1 birinci dereceden momentin karesidir;
m2 - ikinci derecenin anı
(istatistiksel bir popülasyonda bir özellik yalnızca iki birbirini dışlayan seçenek olacak şekilde değişirse, bu tür değişkenliğe alternatif denir) aşağıdaki formül kullanılarak hesaplanabilir:

Bu dağılım formülünde q = 1-p'yi yerine koyarsak şunu elde ederiz:

Varyans türleri
Toplam varyans Bir özelliğin, bu varyasyona neden olan tüm faktörlerin etkisi altında popülasyonun tamamındaki değişimini bir bütün olarak ölçer. Bir x karakteristiğinin bireysel değerlerinin, x'in genel ortalama değerinden sapmalarının ortalama karesine eşittir ve basit varyans veya ağırlıklı varyans olarak tanımlanabilir.
rastgele değişimi karakterize eder, yani Değişimin hesaba katılmayan faktörlerin etkisinden kaynaklanan ve grubun temelini oluşturan faktör özelliğine bağlı olmayan kısmı. Bu tür bir dağılım, X grubu içindeki özelliğin bireysel değerlerinin grubun aritmetik ortalamasından sapmalarının ortalama karesine eşittir ve basit dağılım veya ağırlıklı dağılım olarak hesaplanabilir.
Böylece, grup içi varyans ölçümleri Bir grup içindeki bir özelliğin varyasyonu aşağıdaki formülle belirlenir:

burada xi grup ortalamasıdır;
ni gruptaki birimlerin sayısıdır.
Örneğin, bir atölyede işçilerin niteliklerinin işgücü üretkenliği düzeyi üzerindeki etkisini inceleme görevinde belirlenmesi gereken grup içi farklılıklar, her gruptaki çıktıda tüm olası faktörlerin (ekipmanın teknik durumu, ekipmanın mevcudiyeti) neden olduğu değişiklikleri gösterir. araç ve gereçler, işçilerin yaşı, iş yoğunluğu vb.), nitelik kategorisindeki farklılıklar hariç (bir grup içindeki tüm işçiler aynı niteliklere sahiptir).
Grup içi varyansların ortalaması, rastgeleliği, yani varyasyonun gruplandırma faktörü haricindeki tüm diğer faktörlerin etkisi altında meydana gelen kısmını yansıtır. Aşağıdaki formül kullanılarak hesaplanır:

Grubun temelini oluşturan faktör işaretinin etkisinden kaynaklanan, ortaya çıkan özelliğin sistematik varyasyonunu karakterize eder. Grup ortalamalarının genel ortalamadan sapmalarının ortalama karesine eşittir. Gruplar arası varyans aşağıdaki formül kullanılarak hesaplanır:

İstatistiklere varyans ekleme kuralı
Buna göre varyans ekleme kuralı toplam varyans, grup içi ve gruplar arası varyansların ortalamasının toplamına eşittir:
![]()
Bu kuralın anlamı tüm faktörlerin etkisi altında ortaya çıkan toplam varyansın, diğer tüm faktörlerin etkisi altında ortaya çıkan varyanslar ile gruplama faktöründen dolayı ortaya çıkan varyansın toplamına eşit olmasıdır.
Varyans ekleme formülünü kullanarak, bilinen iki varyanstan üçüncü bilinmeyen varyansı belirleyebilir ve ayrıca gruplandırma özelliğinin etkisinin gücünü değerlendirebilirsiniz.
Dispersiyon özellikleri
1. Bir özelliğin tüm değerleri aynı sabit miktarda azaltılırsa (artırılırsa) dağılım değişmeyecektir.
2. Bir özelliğin tüm değerleri aynı sayıda n kadar azaltılırsa (artırılırsa), varyans buna karşılık olarak n^2 kat azalacak (artacaktır).
Adımlar
Örnek varyansının hesaplanması
-
Örnek değerleri kaydedin.Çoğu durumda istatistikçiler yalnızca belirli popülasyonların örneklerine erişebilir. Örneğin, kural olarak, istatistikçiler Rusya'daki tüm arabaların toplamını korumanın maliyetini analiz etmiyorlar - birkaç bin arabadan oluşan rastgele bir örneği analiz ediyorlar. Böyle bir örnek, bir arabanın ortalama maliyetini belirlemeye yardımcı olacaktır, ancak büyük olasılıkla ortaya çıkan değer gerçek değerden uzak olacaktır.
- Örneğin, bir kafede 6 gün boyunca satılan çörek sayısını rastgele sırayla analiz edelim. Örnek şuna benzer: 17, 15, 23, 7, 9, 13. Bu bir popülasyon değil örnektir çünkü kafenin açık olduğu her gün için satılan çöreklere ilişkin verimiz yoktur.
- Size bir değer örneği yerine bir popülasyon verildiyse bir sonraki bölüme geçin.
-
Örnek varyansını hesaplamak için bir formül yazın. Dağılım, belirli bir miktardaki değerlerin yayılımının bir ölçüsüdür. Varyans değeri sıfıra ne kadar yakınsa değerler birbirine o kadar yakın gruplanır. Bir değer örneğiyle çalışırken varyansı hesaplamak için aşağıdaki formülü kullanın:
- s 2 (\displaystyle s^(2)) = ∑[(x ben (\displaystyle x_(i))- X) 2 (\displaystyle ^(2))] / (n-1)
- s 2 (\displaystyle s^(2))– bu dağılımdır. Dağılım birim kare cinsinden ölçülür.
- x ben (\displaystyle x_(i))– numunedeki her değer.
- x ben (\displaystyle x_(i)) x̅'i çıkarmanız, karesini almanız ve ardından sonuçları eklemeniz gerekir.
- x̅ – örnek ortalaması (örnek ortalaması).
- n – örnekteki değerlerin sayısı.
-
Örnek ortalamasını hesaplayın. X̅ olarak gösterilir. Örnek ortalaması basit bir aritmetik ortalama olarak hesaplanır: örnekteki tüm değerleri toplayın ve ardından sonucu örnekteki değer sayısına bölün.
- Örneğimizde örnekteki değerleri toplayın: 15 + 17 + 23 + 7 + 9 + 13 = 84
Şimdi sonucu örnekteki değer sayısına bölün (örneğimizde 6 tane var): 84 ÷ 6 = 14.
Örnek ortalama x̅ = 14. - Örnek ortalaması, örnekteki değerlerin etrafında dağıldığı merkezi değerdir. Örnek kümedeki değerler örnek ortalamanın etrafında ise varyans küçüktür; aksi takdirde varyans büyüktür.
- Örneğimizde örnekteki değerleri toplayın: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Örnek ortalamasını örnekteki her değerden çıkarın.Şimdi farkı hesaplayın x ben (\displaystyle x_(i))- x̅, nerede x ben (\displaystyle x_(i))– numunedeki her değer. Elde edilen her sonuç, belirli bir değerin örneklem ortalamasından sapma derecesini, yani bu değerin örneklem ortalamasından ne kadar uzakta olduğunu gösterir.
- Örneğimizde:
x 1 (\displaystyle x_(1))- x = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - Toplamlarının sıfıra eşit olması gerektiğinden elde edilen sonuçların doğruluğunu kontrol etmek kolaydır. Bu, ortalamanın tanımıyla ilgilidir, çünkü negatif değerler (ortalamadan daha küçük değerlere olan mesafeler) pozitif değerlerle (ortalamadan daha büyük değerlere olan mesafeler) tamamen dengelenir.
- Örneğimizde:
-
Yukarıda belirtildiği gibi farkların toplamı x ben (\displaystyle x_(i))- x̅ sıfıra eşit olmalıdır. Bu, ortalama varyansın her zaman sıfır olduğu anlamına gelir ve bu da belirli bir miktardaki değerlerin yayılımı hakkında herhangi bir fikir vermez. Bu sorunu çözmek için her farkın karesini alın x ben (\displaystyle x_(i))- X. Bu, yalnızca pozitif sayılar elde etmenize neden olur ve bunların toplamı hiçbir zaman 0'a eşit olmaz.
- Örneğimizde:
(x 1 (\displaystyle x_(1))- X) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))- X) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Farkın karesini buldunuz - x̅) 2 (\displaystyle ^(2))Örnekteki her değer için.
- Örneğimizde:
-
Farkların karelerinin toplamını hesaplayın. Yani formülün şu şekilde yazılan kısmını bulun: ∑[( x ben (\displaystyle x_(i))- X) 2 (\displaystyle ^(2))] Burada Σ işareti her değer için kare farkların toplamı anlamına gelir x ben (\displaystyle x_(i))örnekte. Kare farklarını zaten buldunuz (x ben (\displaystyle (x_(i))- X) 2 (\displaystyle ^(2)) her değer için x ben (\displaystyle x_(i))örnekte; şimdi sadece bu kareleri ekleyin.
- Örneğimizde: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Sonucu n - 1'e bölün; burada n, örnekteki değerlerin sayısıdır. Bir süre önce, örneklem varyansını hesaplamak için istatistikçiler sonucu basitçe n'ye bölüyordu; bu durumda, belirli bir örneğin varyansını tanımlamak için ideal olan kare varyansın ortalamasını elde edersiniz. Ancak herhangi bir örneğin değer popülasyonunun yalnızca küçük bir kısmı olduğunu unutmayın. Başka bir örnek alıp aynı hesaplamaları yaparsanız farklı bir sonuç elde edersiniz. Görünen o ki, (sadece n yerine) n - 1'e bölmek, ilgilendiğiniz şey olan popülasyon varyansının daha doğru bir tahminini veriyor. N – 1'e bölme yaygın hale geldi, bu nedenle örnek varyansını hesaplama formülüne dahil edildi.
- Örneğimizde örnek 6 değer içermektedir, yani n = 6.
Örneklem varyansı = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- Örneğimizde örnek 6 değer içermektedir, yani n = 6.
-
Varyans ve standart sapma arasındaki fark. Formülün bir üs içerdiğini, dolayısıyla dağılımın analiz edilen değerin birim kare cinsinden ölçüldüğünü unutmayın. Bazen böyle bir büyüklüğün işletilmesi oldukça zordur; bu gibi durumlarda varyansın kareköküne eşit olan standart sapmayı kullanın. Bu nedenle örneklem varyansı şu şekilde gösterilir: s 2 (\displaystyle s^(2)) ve numunenin standart sapması şu şekildedir: s (\displaystyle s).
- Örneğimizde numunenin standart sapması: s = √33,2 = 5,76.
Nüfus Varyansının Hesaplanması
-
Bazı değer kümelerini analiz edin. Set, söz konusu miktarın tüm değerlerini içerir. Örneğin, Leningrad bölgesi sakinlerinin yaşını inceliyorsanız, toplam bu bölgenin tüm sakinlerinin yaşını içerir. Bir popülasyonla çalışırken bir tablo oluşturularak nüfus değerlerinin bu tabloya girilmesi önerilir. Aşağıdaki örneği düşünün:
- Belirli bir odada 6 adet akvaryum bulunmaktadır. Her akvaryumda aşağıdaki sayıda balık bulunur:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- Belirli bir odada 6 adet akvaryum bulunmaktadır. Her akvaryumda aşağıdaki sayıda balık bulunur:
-
Popülasyon varyansını hesaplamak için bir formül yazın. Popülasyon belirli bir miktarın tüm değerlerini içerdiğinden aşağıdaki formül popülasyon varyansının tam değerini elde etmenizi sağlar. Nüfus varyansını örneklem varyansından (ki bu yalnızca bir tahmindir) ayırt etmek için istatistikçiler çeşitli değişkenler kullanır:
- σ 2 (\displaystyle ^(2)) = (∑(x ben (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/N
- σ 2 (\displaystyle ^(2))– nüfus dağılımı (“sigma kare” olarak okunur). Dağılım birim kare cinsinden ölçülür.
- x ben (\displaystyle x_(i))– her değer kendi bütünlüğü içinde.
- Σ – toplam işareti. Yani her değerden x ben (\displaystyle x_(i))μ'yu çıkarmanız, karesini almanız ve ardından sonuçları eklemeniz gerekir.
- μ – nüfus ortalaması.
- n – popülasyondaki değerlerin sayısı.
-
Nüfus ortalamasını hesaplayın. Bir popülasyonla çalışırken ortalaması μ (mu) olarak gösterilir. Popülasyon ortalaması basit bir aritmetik ortalama olarak hesaplanır: popülasyondaki tüm değerleri toplayın ve ardından sonucu popülasyondaki değer sayısına bölün.
- Ortalamaların her zaman aritmetik ortalama olarak hesaplanmadığını unutmayın.
- Örneğimizde popülasyonun anlamı: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Popülasyondaki her değerden popülasyon ortalamasını çıkarın. Fark değeri sıfıra ne kadar yakınsa, spesifik değer popülasyon ortalamasına o kadar yakındır. Popülasyondaki her değer ile ortalaması arasındaki farkı bulun ve değerlerin dağılımı hakkında ilk fikri elde edeceksiniz.
- Örneğimizde:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- Örneğimizde:
-
Elde edilen her sonucun karesini alın. Fark değerleri hem pozitif hem de negatif olacaktır; Bu değerler bir sayı doğrusu üzerinde çizilirse popülasyon ortalamasının sağında ve solunda yer alacaktır. Bu, varyansın hesaplanması için iyi değildir çünkü pozitif ve negatif sayılar birbirini iptal eder. Yani tamamen pozitif sayılar elde etmek için her farkın karesini alın.
- Örneğimizde:
(x ben (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) her popülasyon değeri için (i = 1'den i = 6'ya):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Nerede x n (\displaystyle x_(n))– popülasyondaki son değer. - Elde edilen sonuçların ortalama değerini hesaplamak için toplamlarını bulup n'ye bölmeniz gerekir:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/N
- Şimdi yukarıdaki açıklamayı değişkenleri kullanarak yazalım: (∑( x ben (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n ve popülasyon varyansını hesaplamak için bir formül elde edin.
- Örneğimizde:
 (1 ortalama olarak derecelendirmeler: 5,00 5 üzerinden)
(1 ortalama olarak derecelendirmeler: 5,00 5 üzerinden)